
ZUSAMMENFASSUNG
Message Queues 2026: Dein Guide für asynchrone Kommunikation
Entdecke, wie Message Queues die Skalierbarkeit, Robustheit und Effizienz moderner Backend-Systeme revolutionieren.
Keywords: Message Queue, Asynchrone Kommunikation, Skalierbare Architekturen
EINLEITUNG
1. Die Notwendigkeit asynchroner Kommunikation im Jahr 2026
Im Jahr 2026 sind die Anforderungen an moderne Backend-Systeme komplexer denn je. Benutzer erwarten blitzschnelle Reaktionen, selbst bei hohem Datenverkehr, und Anwendungen müssen ständig verfügbar sein, selbst wenn einzelne Komponenten ausfallen. Gleichzeitig treiben die Verbreitung von Microservices-Architekturen und Cloud-nativen Ansätzen die Notwendigkeit einer effizienten und robusten Kommunikation zwischen Diensten voran. Hier spielen Message Queues eine entscheidende Rolle, indem sie asynchrone Kommunikationsmuster ermöglichen, die diese Herausforderungen bewältigen.
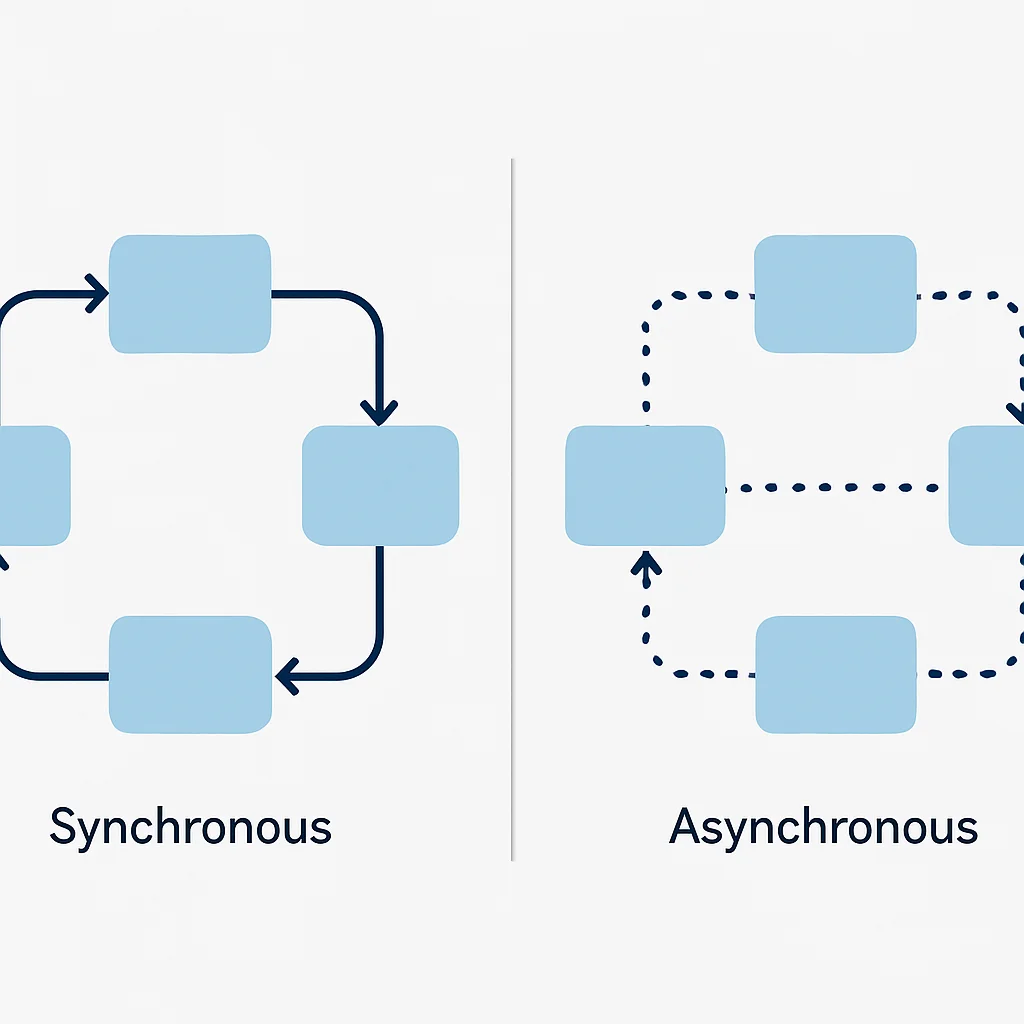
Traditionell erfolgte die Kommunikation in vielen Systemen synchron: Ein Dienst ruft einen anderen direkt auf und wartet auf dessen Antwort. Während dieser Ansatz für einfache, monolithische Anwendungen ausreichend sein mag, stößt er in verteilten Systemen schnell an seine Grenzen. Ein langsamer oder ausgefallener Dienst kann eine Kaskade von Fehlern auslösen und die gesamte Anwendung zum Stillstand bringen. Zudem skaliert die synchrone Kommunikation schlecht, da jeder Aufruf eine direkte Abhängigkeit schafft und Ressourcen bindet, während auf eine Antwort gewartet wird.
Asynchrone Kommunikation hingegen entkoppelt die Dienste voneinander. Wenn Dienst A eine Aufgabe an Dienst B übergeben möchte, sendet er eine Nachricht an eine Message Queue und fährt sofort mit seiner Arbeit fort. Dienst B holt die Nachricht ab, sobald er dazu bereit ist, und verarbeitet sie. Dies eliminiert direkte Abhängigkeiten und Wartezeiten, was zu einer Reihe von Vorteilen führt, die für die Entwicklung robuster und skalierbarer Backends im Jahr 2026 unerlässlich sind:
- Entkopplung: Dienste kennen sich nicht direkt. Sie kommunizieren über die Message Queue, was die Systemkomplexität reduziert und die Wartbarkeit verbessert. Dienste können unabhängig voneinander entwickelt, bereitgestellt und skaliert werden.
- Skalierbarkeit: Die Anzahl der Consumer, die Nachrichten aus einer Queue verarbeiten, kann dynamisch angepasst werden, um Lastspitzen zu bewältigen. Producer können Nachrichten senden, ohne sich um die Verfügbarkeit oder Kapazität der Consumer kümmern zu müssen.
- Resilienz: Wenn ein Consumer ausfällt, bleiben die Nachrichten in der Queue erhalten und können von einem anderen Consumer oder nach dem Neustart des ausgefallenen Dienstes verarbeitet werden. Dies verhindert Datenverlust und erhöht die Fehlertoleranz des Systems.
- Lastverteilung: Message Queues verteilen die Arbeitslast effizient auf mehrere Consumer, was eine gleichmäßige Auslastung der Ressourcen gewährleistet.
- Pufferung: Queues können als Puffer fungieren, um temporäre Lastspitzen abzufangen, wenn die Producer-Rate die Consumer-Rate übersteigt.
KERNPUNKT
Message Queues sind das Rückgrat moderner, verteilter Backend-Architekturen im Jahr 2026, da sie eine essenzielle Entkopplung, Skalierbarkeit und Resilienz durch asynchrone Kommunikation ermöglichen.
Die Wahl der richtigen Message Queue Technologie und deren korrekte Implementierung sind entscheidend für den Erfolg einer Anwendung. Dieser Guide soll Ihnen einen umfassenden Überblick über die Konzepte, die gängigsten Technologien und bewährte Verfahren geben, damit Sie fundierte Entscheidungen für Ihre Backend-Architekturen im Jahr 2026 treffen können.
GRUNDLAGEN
2. Grundlagen von Message Queues: Konzepte und Komponenten
Um Message Queues effektiv nutzen zu können, ist ein grundlegendes Verständnis ihrer Kernkonzepte und der beteiligten Komponenten unerlässlich. Obwohl verschiedene Technologien unterschiedliche Implementierungen haben, teilen sie doch ähnliche Prinzipien.
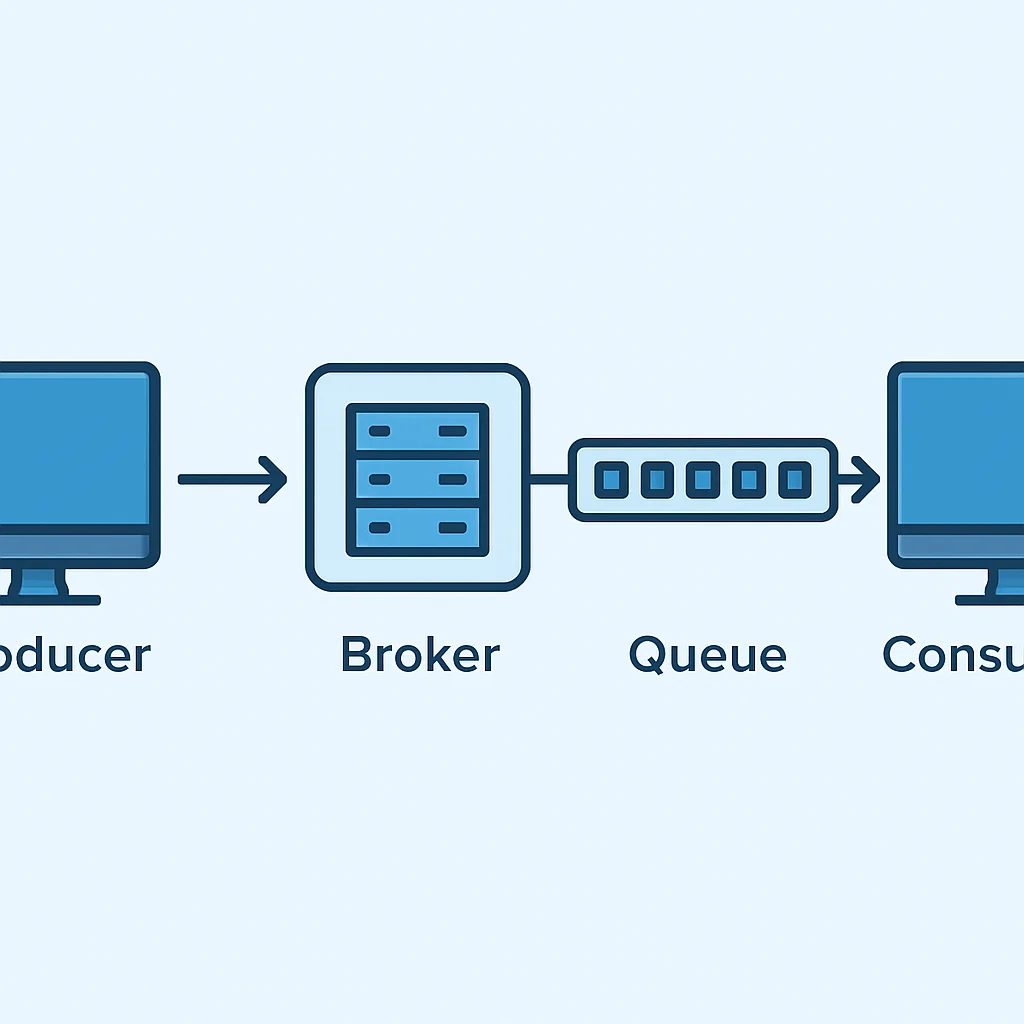
Kernkomponenten einer Message Queue
- Producer (Sender): Dies ist die Anwendung oder der Dienst, der Nachrichten erstellt und an die Message Queue sendet. Der Producer ist in der Regel entkoppelt vom Consumer und muss dessen Verfügbarkeit nicht kennen.
- Consumer (Empfänger): Dies ist die Anwendung oder der Dienst, der Nachrichten von der Message Queue empfängt und verarbeitet. Es können ein oder mehrere Consumer Nachrichten von einer Queue lesen.
- Broker (Server): Der Broker ist das Herzstück des Message Queue Systems. Er ist für die Speicherung, Weiterleitung und Verwaltung der Nachrichten verantwortlich. Er fungiert als Vermittler zwischen Producern und Consumern. Beispiele für Broker sind RabbitMQ, Kafka oder ActiveMQ.
- Queue / Topic: Dies ist der Ort, an dem Nachrichten gespeichert werden, bis sie von einem Consumer abgeholt werden. Der Begriff variiert je nach Messaging-Muster.
- Queue (Warteschlange): Für das Point-to-Point-Messaging. Jede Nachricht wird nur von einem einzigen Consumer verarbeitet.
- Topic (Thema): Für das Publish/Subscribe-Messaging. Eine Nachricht kann von mehreren Consumern empfangen werden, die an diesem Thema interessiert sind.
- Nachricht (Message): Die Daten, die zwischen Producern und Consumern ausgetauscht werden. Eine Nachricht besteht typischerweise aus einem Header (Metadaten wie Nachrichten-ID, Zeitstempel) und einem Body (die eigentlichen Nutzdaten, oft im JSON-, XML- oder Binärformat).
Messaging-Muster: Point-to-Point vs. Publish/Subscribe
Die beiden grundlegenden Messaging-Muster sind entscheidend für das Design Ihrer Kommunikationsstrategie:
- Point-to-Point (P2P): Hierbei sendet ein Producer Nachrichten an eine Queue, und genau ein Consumer empfängt und verarbeitet jede Nachricht. Auch wenn mehrere Consumer an der gleichen Queue horchen, wird jede Nachricht nur einmal zugestellt. Dies ist ideal für Aufgabenverteilung und Lastenausgleich, z.B. bei der Verarbeitung von Bestellungen oder dem Versenden von E-Mails.
- Publish/Subscribe (Pub/Sub): Bei diesem Muster sendet ein Producer (Publisher) Nachrichten an ein Topic (oder einen Exchange, je nach Technologie), und alle interessierten Consumer (Subscriber) erhalten eine Kopie dieser Nachricht. Dies ist perfekt für Event-Streaming, Benachrichtigungssysteme oder Datenreplikation, wo mehrere Dienste auf die gleiche Information reagieren müssen.
Wichtige Konzepte
- Acknowledgement (Bestätigung): Nach dem Empfang und der erfolgreichen Verarbeitung einer Nachricht sendet der Consumer eine Bestätigung (ACK) an den Broker. Erst dann wird die Nachricht aus der Queue entfernt (oder als verarbeitet markiert). Fehlt die Bestätigung (z.B. bei einem Consumer-Absturz), kann der Broker die Nachricht erneut zustellen, um Datenverlust zu vermeiden (At-Least-Once-Delivery).
- Durability (Persistenz): Um Datenverlust bei einem Broker-Neustart zu verhindern, können Nachrichten persistent gespeichert werden. Das bedeutet, sie werden auf die Festplatte geschrieben, bevor sie vom Broker als empfangen bestätigt werden. Dies ist entscheidend für kritische Geschäftsprozesse.
- Message Ordering (Nachrichtenreihenfolge): Einige Systeme garantieren die Reihenfolge der Nachrichten innerhalb einer Queue oder Partition, andere nicht. Für bestimmte Anwendungsfälle (z.B. Finanztransaktionen) ist die strikte Einhaltung der Reihenfolge unerlässlich.
- Dead Letter Queue (DLQ): Eine spezielle Queue, in die Nachrichten verschoben werden, die nicht erfolgreich verarbeitet werden konnten (z.B. nach mehreren fehlgeschlagenen Zustellversuchen oder wenn sie ungültig sind). Dies verhindert, dass fehlerhafte Nachrichten die Haupt-Queue blockieren und ermöglicht eine manuelle Untersuchung und Fehlerbehebung.
KERNPUNKT
Das Verständnis der Kernkomponenten (Producer, Consumer, Broker, Queue/Topic) und Konzepte wie P2P/Pub/Sub-Muster, Acknowledgement, Durability und DLQs ist fundamental für das Design robuster Messaging-Lösungen.
TECHNOLOGIEVERGLEICH
3. Die Top Message Queue Technologien im Vergleich (2026)
Die Landschaft der Message Queue Technologien ist vielfältig, und die Wahl des richtigen Tools hängt stark von den spezifischen Anforderungen Ihres Projekts ab. Im Jahr 2026 dominieren weiterhin einige etablierte Player, während Cloud-native Dienste immer mehr an Bedeutung gewinnen. Hier stellen wir die wichtigsten Optionen vor und vergleichen ihre Stärken und Schwächen.
Apache Kafka: Der Streaming-Gigant
Apache Kafka ist weit mehr als eine traditionelle Message Queue; es ist eine verteilte Streaming-Plattform, die für hohe Durchsätze und Echtzeit-Datenverarbeitung konzipiert wurde. Es ist ideal für Szenarien, die eine persistente Speicherung von Nachrichten und die Verarbeitung von Datenströmen erfordern.
- Stärken: Extrem hoher Durchsatz (Millionen von Nachrichten pro Sekunde), hohe Fehlertoleranz durch Replikation, permanente Speicherung von Nachrichten (Event Log), Skalierbarkeit durch Partitionierung, Unterstützung für Stream-Verarbeitung (Kafka Streams, KSQL).
- Schwachpunkte: Höhere Komplexität in Einrichtung und Betrieb, nicht ideal für traditionelles Point-to-Point-Messaging mit sehr geringer Latenz bei einzelnen Nachrichten, da es auf Batching optimiert ist.
- Anwendungsfälle: Log-Aggregation, Echtzeit-Monitoring, Event Sourcing, Datenintegration, IoT-Datenpipelines, Microservices-Kommunikation in Event-Driven Architectures.
CODE-ERKLÄRUNG
Beispiel für einen einfachen Kafka Producer und Consumer in Python unter Verwendung der confluent-kafka Bibliothek. Der Producer sendet eine Nachricht an das Topic ‚mein_topic‘, und der Consumer empfängt sie.
# Kafka Producer Beispiel (Python)
from confluent_kafka import Producer
import socket
conf = {'bootstrap.servers': 'localhost:9092',
'client.id': socket.gethostname()}
producer = Producer(conf)
def delivery_report(err, msg):
if err is not None:
print(f"Nachrichtenzustellung fehlgeschlagen: {err}")
else:
print(f"Nachricht erfolgreich gesendet an {msg.topic()} [{msg.partition()}] @ {msg.offset()}")
# Sende eine Nachricht
producer.produce('mein_topic', key="key1", value="Hallo von Kwonnen!", callback=delivery_report)
producer.flush()
print("Producer: Nachricht gesendet.")
# Kafka Consumer Beispiel (Python)
from confluent_kafka import Consumer, KafkaException
conf = {'bootstrap.servers': 'localhost:9092',
'group.id': 'meine_consumer_gruppe',
'auto.offset.reset': 'earliest'}
consumer = Consumer(conf)
try:
consumer.subscribe(['mein_topic'])
while True:
msg = consumer.poll(timeout=1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaException._PARTITION_EOF:
# End of partition event
sys.stderr.write('%% %s [%d] Ende der Partition erreicht bei Offset %d\n' %
(msg.topic(), msg.partition(), msg.offset()))
elif msg.error():
raise KafkaException(msg.error())
else:
# Nachricht erfolgreich empfangen
print(f"Consumer: Empfangen: {msg.value().decode('utf-8')} (Offset: {msg.offset()})")
except KeyboardInterrupt:
pass
finally:
consumer.close()
print("Consumer: Beendet.")
KERNPUNKT
Kafka ist die bevorzugte Wahl für hochskalierbare Echtzeit-Datenströme und Event-Driven Architectures, die eine dauerhafte Speicherung von Ereignissen erfordern.
RabbitMQ: Der vielseitige Nachrichtenbroker
RabbitMQ ist ein klassischer, robuster Message Broker, der das Advanced Message Queuing Protocol (AMQP) implementiert. Es ist bekannt für seine Flexibilität bei Routing-Regeln und die breite Unterstützung verschiedener Messaging-Muster.
- Stärken: Ausgezeichnete Unterstützung für komplexe Routing-Muster (über Exchanges), vielseitig einsetzbar für Point-to-Point und Publish/Subscribe, breite Sprachunterstützung, gute Dokumentation, ausgereifte Features wie Dead Letter Exchanges und Time-to-Live (TTL) für Nachrichten.
- Schwachpunkte: Geringerer Durchsatz als Kafka bei sehr hohem Volumen, Nachrichten werden nach Konsum standardmäßig entfernt (kein permanenter Event Log wie bei Kafka), Skalierung kann komplexer sein als bei Cloud-nativen Diensten.
- Anwendungsfälle: Task Queues für Hintergrundaufgaben, asynchrone API-Anfragen, Microservices-Kommunikation mit komplexen Routing-Anforderungen, Webhooks, RPC (Remote Procedure Call) über Messaging.
CODE-ERKLÄRUNG
Ein einfaches Python-Beispiel für einen RabbitMQ Producer und Consumer unter Verwendung der pika Bibliothek. Der Producer sendet eine Nachricht an die Queue ‚hallo_kwonnen‘, die dann vom Consumer empfangen wird.
# RabbitMQ Producer Beispiel (Python)
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hallo_kwonnen')
message = "Hallo von Kwonnen, RabbitMQ!"
channel.basic_publish(exchange='',
routing_key='hallo_kwonnen',
body=message)
print(f"Producer: Nachricht gesendet: '{message}'")
connection.close()
# RabbitMQ Consumer Beispiel (Python)
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hallo_kwonnen')
def callback(ch, method, properties, body):
print(f"Consumer: Empfangen: '{body.decode()}'")
ch.basic_ack(delivery_tag=method.delivery_tag) # Bestätigung senden
channel.basic_consume(queue='hallo_kwonnen', on_message_callback=callback)
print('Consumer: Warte auf Nachrichten. Zum Beenden STRG+C drücken.')
channel.start_consuming()
KERNPUNKT
RabbitMQ ist die erste Wahl für Anwendungen, die flexible Routing-Muster, robuste Task Queues und eine breite Protokollunterstützung schätzen.
ActiveMQ / Artemis: Der Enterprise-Standard
Apache ActiveMQ (und sein Nachfolger Artemis) ist ein robuster und vielseitiger Open-Source-Nachrichtenbroker, der breite Protokollunterstützung (JMS, AMQP, MQTT, STOMP) bietet. Er ist besonders in Java-Enterprise-Umgebungen verbreitet.
- Stärken: Umfassende JMS-Unterstützung (Java Message Service), hohe Kompatibilität mit verschiedenen Protokollen, gute Integration in Java-Ökosysteme, ausgereifte Funktionen für Clustering und Persistenz.
- Schwachpunkte: Kann bei extrem hohen Durchsätzen an Grenzen stoßen, Konfiguration und Management können komplex sein.
- Anwendungsfälle: Enterprise Application Integration, Legacy-Systeme-Integration, Java-basierte Microservices, die JMS nutzen.
Cloud-native Messaging-Dienste (AWS SQS, Azure Service Bus, Google Pub/Sub)
Für cloud-native Architekturen bieten die großen Cloud-Anbieter vollständig verwaltete Messaging-Dienste an. Diese Dienste eliminieren den operativen Overhead für die Verwaltung der Broker-Infrastruktur.
- AWS Simple Queue Service (SQS): Ein hochskalierbarer, vollständig verwalteter Warteschlangendienst. Bietet Standard-Queues (At-Least-Once-Delivery, Best-Effort Ordering) und FIFO-Queues (Exactly-Once-Processing, strikte Nachrichtenreihenfolge). Ideal für Task Queues und Entkopplung von Microservices.
- Azure Service Bus: Ein vielseitiger Enterprise-Messaging-Dienst, der Queues und Topics unterstützt. Bietet erweiterte Funktionen wie Message Sessions, Dead-Lettering und Transaktionen. Gut geeignet für komplexe Enterprise-Integrationsszenarien.
- Google Cloud Pub/Sub: Ein globaler, skalierbarer Echtzeit-Messaging-Dienst, der das Publish/Subscribe-Muster implementiert. Ideal für Event-Driven Architectures, Echtzeit-Datenströme und die Integration von Anwendungen über Regionen hinweg.
- Stärken: Keine Serververwaltung, automatische Skalierung, hohe Verfügbarkeit, Pay-as-you-go-Modell, nahtlose Integration in die jeweilige Cloud-Plattform.
- Schwachpunkte: Vendor Lock-in, Kosten können bei sehr hohem Volumen steigen, weniger Kontrolle über die Broker-Konfiguration.
Vergleichstabelle der Message Queue Technologien (2026)
Die folgende Tabelle bietet einen schnellen Überblick über die wichtigsten Merkmale der besprochenen Technologien:
| Merkmal | Apache Kafka | RabbitMQ | ActiveMQ Artemis | Cloud Services (SQS/Azure SB/GCP Pub/Sub) |
|---|---|---|---|---|
| Primäre Anwendungsfälle | Event Streaming, Log Aggregation, Echtzeit-Analytics | Task Queues, komplexe Routing-Muster, RPC | Enterprise Integration, JMS-basierte Anwendungen | Serverless, Microservices-Entkopplung, Skalierbarkeit ohne Ops |
| Nachrichtenspeicherung | Permanent (konfigurierbare Retention), Event Log | Temporär (bis konsumiert/ACK), kein Event Log | Persistent über Journal/DB, konfigurierbare Retention | Variiert (z.B. SQS kurzfristig, Pub/Sub 7 Tage) |
| Durchsatz | Sehr hoch (Millionen/Sekunde) | Hoch (Zehntausende/Sekunde) | Mittel bis Hoch | Sehr hoch (automatisch skaliert) |
| Latenz | Niedrig (Millisekunden) | Sehr niedrig (Mikrosekunden bis Millisekunden) | Niedrig | Niedrig (variiert je nach Dienst) |
| Komplexität (Setup/Ops) | Hoch | Mittel | Mittel bis Hoch | Niedrig (Managed Service) |
| Messaging-Muster | Pub/Sub (Topics mit Partionen) | P2P (Queues), Pub/Sub (Exchanges) | P2P (Queues), Pub/Sub (Topics) | Variiert (z.B. SQS P2P, Pub/Sub Pub/Sub) |
Die Wahl der richtigen Technologie hängt von Faktoren wie dem benötigten Durchsatz, der Latenz, der Komplexität der Routing-Anforderungen, der Notwendigkeit einer dauerhaften Nachrichtenspeicherung und der Präferenz für Self-Hosting oder Managed Services ab. Für neue Projekte in der Cloud ist die Nutzung von Managed Services oft die einfachste und kostengünstigste Option, während Kafka für hochskalierbare Event-Streaming-Plattformen und RabbitMQ für vielseitige Task Queues weiterhin eine starke Rolle spielen.
IMPLEMENTIERUNG
4. Herausforderungen und Best Practices bei der Implementierung
Die Implementierung von Message Queues ist nicht trivial und birgt spezifische Herausforderungen. Ein fundiertes Verständnis dieser Probleme und die Anwendung bewährter Praktiken sind entscheidend, um robuste und zuverlässige Systeme aufzubauen.
Herausforderung 2: Umgang mit Fehlern und Dead Letter Queues (DLQ)
Nicht jede Nachricht kann erfolgreich verarbeitet werden. Gründe hierfür können fehlerhafte Daten, temporäre Abhängigkeitsausfälle oder Bugs im Consumer sein. Wenn ein Consumer eine Nachricht nicht verarbeiten kann und keine Bestätigung sendet, wird die Nachricht in der Regel erneut zugestellt. Dies kann zu Endlosschleifen führen, die die Queue blockieren und die Systemleistung beeinträchtigen.
Best Practice: Implementieren Sie eine Dead Letter Queue (DLQ). Nachrichten, die nach einer bestimmten Anzahl von Wiederholungsversuchen immer noch nicht verarbeitet werden können, werden automatisch in die DLQ verschoben. Dort können sie manuell inspiziert, korrigiert und erneut in die Haupt-Queue gestellt werden, oder sie werden dauerhaft archiviert. Dies verhindert, dass „giftige“ Nachrichten das System lahmlegen und ermöglicht eine gezielte Fehleranalyse.
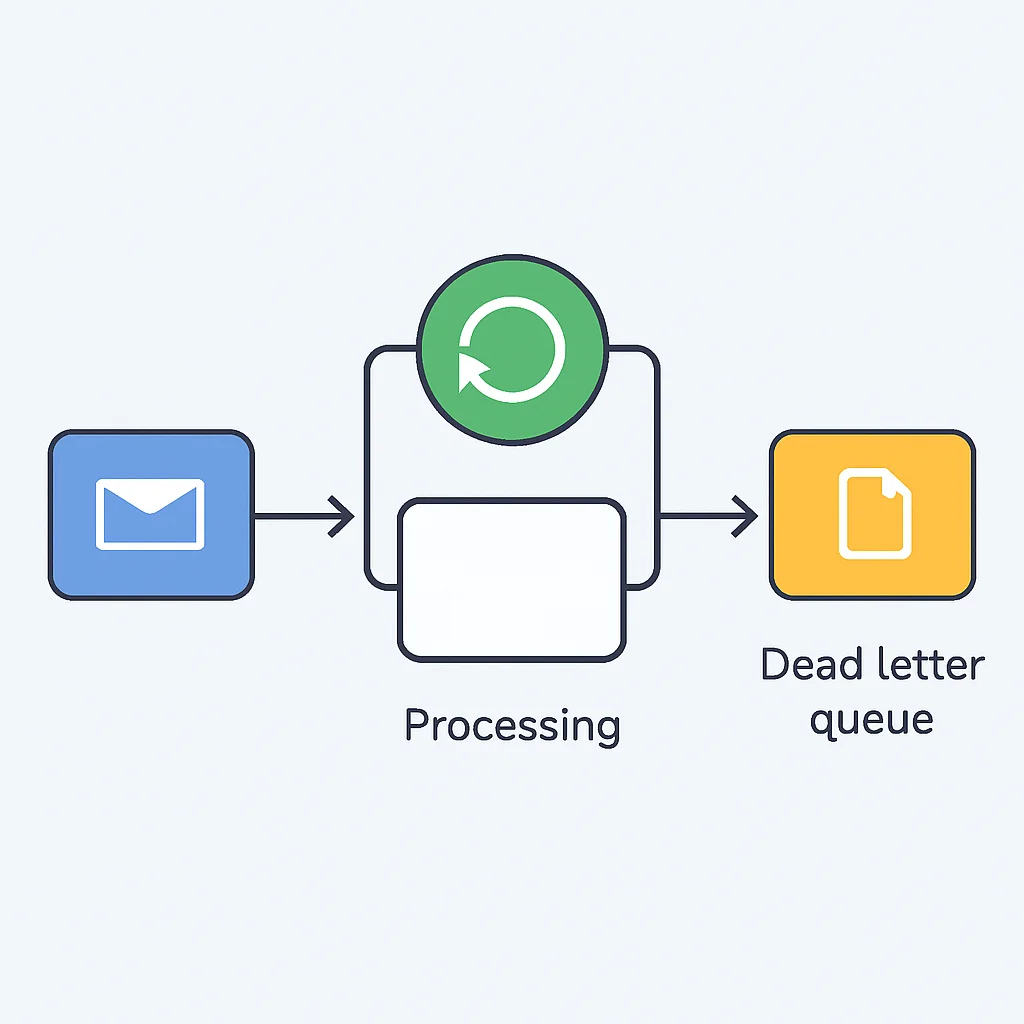
Herausforderung 3: Monitoring und Observability
In verteilten Systemen ist es entscheidend, den Zustand Ihrer Message Queues zu überwachen. Ohne angemessenes Monitoring können Sie Probleme wie blockierte Queues, zu langsame Consumer oder einen wachsenden Backlog von Nachrichten nicht rechtzeitig erkennen.
Best Practice: Sammeln Sie Metriken von Ihrem Message Broker und Ihren Consumern. Wichtige Metriken umfassen:
- Anzahl der Nachrichten in der Queue (Backlog): Ein ständig wachsender Backlog deutet auf zu langsame Consumer oder unzureichende Skalierung hin.
- Nachrichten-Ein-/Ausgaberate: Zeigt den Durchsatz des Systems an.
- Consumer-Latenz / Processing-Zeit: Wie lange braucht ein Consumer, um eine Nachricht zu verarbeiten?
- Anzahl der DLQ-Nachrichten: Ein Anstieg hier deutet auf wiederkehrende Fehler in der Nachrichtenverarbeitung hin.
- Fehlerraten bei Producern/Consumern: Zeigt Probleme beim Senden oder Empfangen von Nachrichten.
Nutzen Sie Tools wie Prometheus, Grafana, Datadog oder die Monitoring-Dienste Ihrer Cloud-Anbieter, um diese Metriken zu visualisieren und Alarme bei Schwellenwertüberschreitungen einzurichten.
Best Practice 1: Nachrichtenschema-Management
In verteilten Systemen, in denen verschiedene Dienste Nachrichten austauschen, ist es entscheidend, die Struktur (das Schema) der Nachrichten zu verwalten. Schemaänderungen können zu Kompatibilitätsproblemen zwischen Producern und Consumern führen.
Lösung: Verwenden Sie ein Schema Registry (z.B. Confluent Schema Registry für Kafka) und definieren Sie Ihre Nachrichtenschemata (z.B. mit Avro, Protobuf oder JSON Schema). Dies ermöglicht eine zentrale Verwaltung der Schemata und eine automatische Validierung der Nachrichten, wodurch Kompatibilitätsprobleme frühzeitig erkannt werden.
Best Practice 2: Skalierung der Consumer mit Consumer Groups
Um die Skalierbarkeit und Fehlertoleranz zu maximieren, sollten Sie Ihre Consumer in Consumer Groups organisieren. Eine Consumer Group ist eine Gruppe von Consumern, die gemeinsam Nachrichten von einer oder mehreren Queues/Topics verarbeiten.
- Point-to-Point: In einer P2P-Queue verteilt der Broker Nachrichten gleichmäßig auf die Consumer innerhalb einer Gruppe. Fällt ein Consumer aus, übernehmen die anderen die Arbeit.
- Publish/Subscribe: Bei Pub/Sub erhält jede Consumer Group eine Kopie aller Nachrichten eines Topics. Innerhalb einer Gruppe wird die Last dann auf die einzelnen Consumer verteilt. Dies ermöglicht es verschiedenen Anwendungen, unabhängig voneinander die gleichen Ereignisse zu verarbeiten.
Die dynamische Skalierung von Consumer Groups (z.B. durch Kubernetes Horizontal Pod Autoscaler) ist ein mächtiges Werkzeug, um auf schwankende Lasten zu reagieren und die Systemleistung zu optimieren.
KERNPUNKT
Idempotenz, Dead Letter Queues, robustes Monitoring und effektives Schema-Management sind essenzielle Best Practices, um die Zuverlässigkeit und Wartbarkeit von Message Queue basierten Systemen im Jahr 2026 zu gewährleisten.
ANWENDUNG
5. Praktische Anwendung: Einsatzszenarien in modernen Architekturen
Message Queues sind vielseitige Werkzeuge, die in einer Vielzahl von modernen Architekturen eingesetzt werden können, um die Entkopplung, Skalierbarkeit und Resilienz zu verbessern. Hier sind einige der gängigsten und wirkungsvollsten Anwendungsfälle im Jahr 2026.
Microservices-Kommunikation
In einer Microservices-Architektur ist die Kommunikation zwischen den Diensten eine Kernherausforderung. Message Queues bieten eine ideale Lösung, um Microservices voneinander zu entkoppeln und die synchrone Kommunikation zu minimieren.
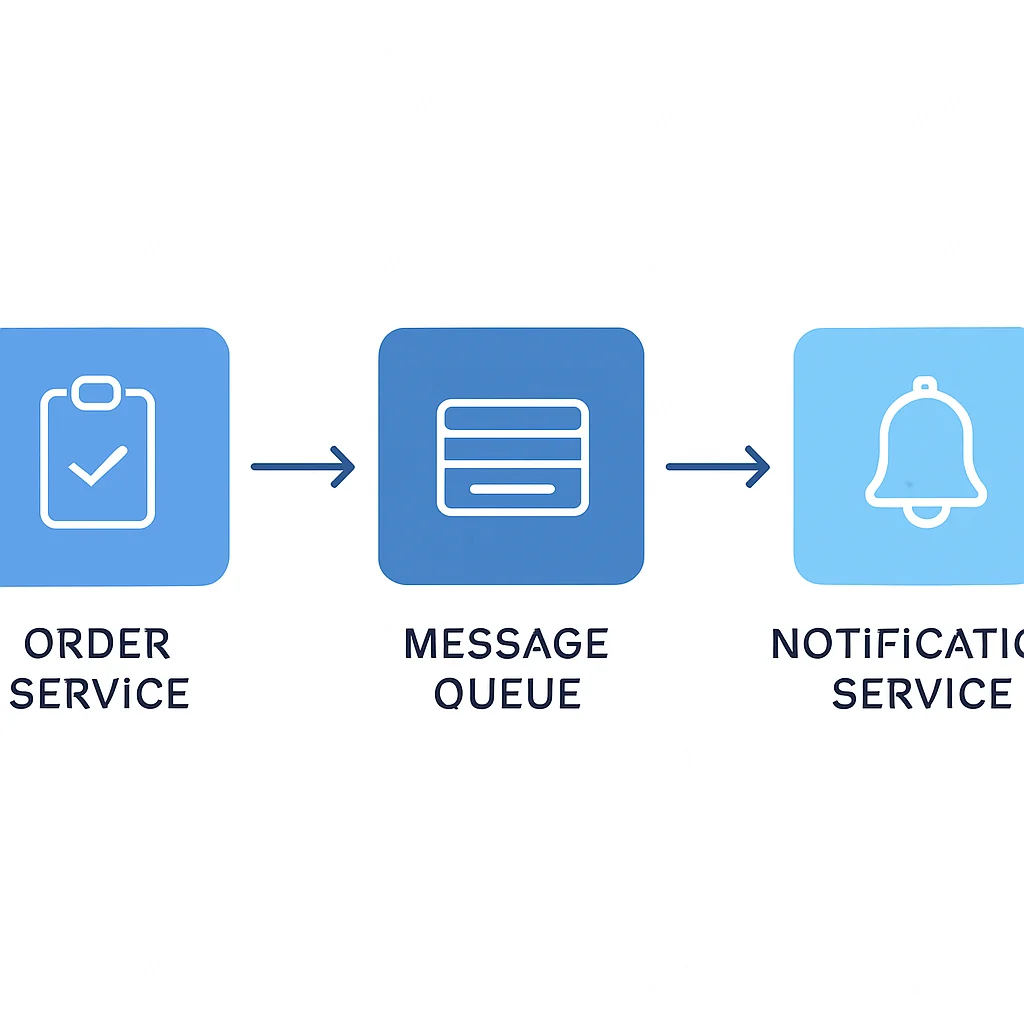
Anwendungsfall: Bestellverarbeitung in einem E-Commerce-System
Wenn ein Kunde eine Bestellung aufgibt, sendet der Bestell-Service eine Nachricht an eine Message Queue (z.B. RabbitMQ oder SQS). Andere Dienste, wie der Zahlungs-Service, der Lagerbestands-Service und der Benachrichtigungs-Service, abonnieren diese Queue oder empfangen die Nachricht. Jeder Dienst verarbeitet die Bestellung unabhängig und asynchron. Fällt der Zahlungsdienst aus, bleibt die Bestellung in der Queue, bis der Dienst wieder verfügbar ist, ohne den Bestell-Service zu blockieren.
Event-Driven Architectures (EDA)
Event-Driven Architectures basieren auf dem Prinzip, dass Systemzustandsänderungen als Ereignisse (Events) veröffentlicht werden, auf die andere Dienste reagieren können. Message Queues, insbesondere Event Streaming Plattformen wie Kafka, sind das Herzstück von EDAs.
Anwendungsfall: Benutzeraktivitätstracking für Personalisierung
Jede Benutzeraktion (Login, Produktansicht, Warenkorb-Update) wird als Ereignis an ein Kafka-Topic gesendet. Ein Analyse-Service konsumiert diese Ereignisse, um Echtzeit-Dashboards zu aktualisieren. Ein separater Personalisierungs-Service nutzt ebenfalls die Ereignisse, um Produktempfehlungen in Echtzeit anzupassen. Beide Dienste arbeiten unabhängig voneinander mit denselben Datenströmen.
Task Queues für Hintergrundaufgaben
Langlaufende oder ressourcenintensive Aufgaben, die nicht sofort erledigt werden müssen, können in Message Queues ausgelagert werden. Dies verbessert die Reaktionszeit der Benutzeroberfläche und die Skalierbarkeit.
Anwendungsfall: Bildverarbeitung in einer Foto-App
Wenn ein Benutzer ein Bild hochlädt, sendet der Webserver eine Nachricht mit dem Speicherort des Bildes an eine RabbitMQ-Queue. Mehrere Worker-Dienste (Consumer) holen diese Nachrichten ab, verarbeiten die Bilder (z.B. Skalierung, Filter anwenden, Metadaten extrahieren) und speichern die Ergebnisse. Der Benutzer erhält sofort eine Bestätigung, während die eigentliche Bildverarbeitung im Hintergrund stattfindet.
Echtzeit-Datenpipelines und Datenintegration
Message Queues sind ideal für den Aufbau von Datenpipelines, die Daten von verschiedenen Quellen sammeln, transformieren und an mehrere Ziele verteilen müssen.
Anwendungsfall: IoT-Datenstrom-Verarbeitung
Sensoren in intelligenten Geräten senden kontinuierlich Daten (Temperatur, Luftfeuchtigkeit, Standort) an ein Kafka-Topic. Ein Streaming-Verarbeitungsdienst (z.B. mit Kafka Streams) aggregiert diese Daten, erkennt Anomalien und sendet Alarme. Gleichzeitig speichert ein anderer Dienst die Rohdaten in einem Data Lake für spätere Analysen. Die Message Queue gewährleistet, dass keine Daten verloren gehen und alle Konsumenten die Daten in Echtzeit verarbeiten können.
KERNPUNKT
Message Queues sind ein Fundament für Microservices-Kommunikation, Event-Driven Architectures, die Verarbeitung von Hintergrundaufgaben und Echtzeit-Datenpipelines, die alle für moderne, skalierbare Backend-Systeme im Jahr 2026 unerlässlich sind.
HÄUFIG GESTELLTE FRAGEN
6. Häufig gestellte Fragen (FAQ)
Q. Wann sollte ich eine Message Queue verwenden und wann nicht?
Sie sollten eine Message Queue verwenden, wenn Sie Entkopplung, Skalierbarkeit, Resilienz oder asynchrone Verarbeitung benötigen, insbesondere in verteilten Systemen und Microservices. Vermeiden Sie sie für synchrone, hochfrequente Anfragen, die eine sofortige Antwort erfordern, oder wenn die zusätzliche Komplexität den Nutzen für sehr einfache Anwendungen überwiegt.
Q. Was ist der Hauptunterschied zwischen Kafka und RabbitMQ?
Kafka ist primär eine verteilte Streaming-Plattform, die für hohe Durchsätze, persistente Speicherung von Events und Stream-Verarbeitung optimiert ist. RabbitMQ ist ein traditioneller Message Broker, der flexible Routing-Muster für Point-to-Point- und Publish/Subscribe-Messaging bietet und Nachrichten nach Konsum in der Regel entfernt.
Q. Wie gehe ich mit Fehlern bei der Nachrichtenverarbeitung um?
Implementieren Sie Wiederholungslogik mit exponentiellem Backoff für temporäre Fehler. Nachrichten, die nach mehreren Versuchen immer noch nicht verarbeitet werden können, sollten an eine Dead Letter Queue (DLQ) gesendet werden, um eine manuelle Untersuchung und Fehlerbehebung zu ermöglichen, ohne die Haupt-Queue zu blockieren.
Q. Was bedeutet „At-Least-Once-Delivery“ und warum ist Idempotenz wichtig?
„At-Least-Once-Delivery“ bedeutet, dass eine Nachricht mindestens einmal zugestellt wird, möglicherweise aber auch mehrmals. Idempotenz ist entscheidend, weil der Consumer so konzipiert sein muss, dass die mehrmalige Verarbeitung derselben Nachricht das gleiche Ergebnis liefert wie die einmalige Verarbeitung, um Dateninkonsistenzen zu vermeiden.
Danke fürs Lesen!
Message Queues sind ein unverzichtbarer Bestandteil moderner Backend-Architekturen im Jahr 2026. Sie ermöglichen es Entwicklern und Architekten, hochskalierbare, resiliente und entkoppelte Systeme zu bauen, die den komplexen Anforderungen gerecht werden. Durch das Verständnis der Kernkonzepte und die bewusste Auswahl der richtigen Technologie können Sie die Leistungsfähigkeit und Zuverlässigkeit Ihrer Anwendungen erheblich steigern.
Fragen? Schreibt es in die Kommentare!