

ZUSAMMENFASSUNG
[Tech-News] Autonome KI-Agenten 2026: Revolutionieren sie die Softwareentwicklung und Automatisierung?
Ein Blick auf die aufkommende Ära der autonomen KI-Agenten und wie sie die Entwicklungsprozesse und die Zukunft der Automatisierung für Entwickler prägen könnten.
Keywords: KI-Agenten, Künstliche Intelligenz, Softwareentwicklung
INHALTSVERZEICHNIS
1. Die Ära der autonomen KI-Agenten: Eine Einführung
2. Autonome KI-Agenten im Detail: Architektur und Anwendung
3. Herausforderungen und Lösungen bei der Implementierung von KI-Agenten
4. Praktische Anwendung: KI-Agenten in der Softwareentwicklung
5. Häufig gestellte Fragen (FAQ)
1. Die Ära der autonomen KI-Agenten: Eine Einführung
Die Technologiewelt ist ständig im Wandel, doch nur selten erleben wir Sprünge, die das Potenzial haben, ganze Industrien grundlegend zu transformieren. Im Jahr 2026 stehen wir an der Schwelle zu einer solchen Revolution: der Ära der autonomen KI-Agenten. Diese Systeme gehen weit über die bisherige Automatisierung hinaus, indem sie nicht nur vorprogrammierte Aufgaben ausführen, sondern eigenständig Probleme erkennen, Lösungen planen, diese umsetzen und aus ihren Erfahrungen lernen können. Für die Softwareentwicklung und Automatisierung bedeutet dies einen Paradigmenwechsel, der die Effizienz und Innovationskraft auf ein neues Niveau heben könnte.
Traditionelle Automatisierungssysteme sind reaktiv; sie reagieren auf vordefinierte Ereignisse oder Anweisungen. Autonome KI-Agenten hingegen sind proaktiv und zielorientiert. Sie können komplexe Ziele in kleinere, handhabbare Schritte zerlegen, die notwendigen Werkzeuge auswählen und verwenden, und sogar ihre eigenen Strategien anpassen, wenn sie auf unerwartete Hindernisse stoßen. Diese Fähigkeit zur Selbstorganisation und Adaption macht sie zu einem Game Changer in Bereichen, die von dynamischen und unvorhersehbaren Herausforderungen geprägt sind, wie es in der modernen Softwareentwicklung der Fall ist.
Die steigende Komplexität von Softwareprojekten, der Druck zu schnelleren Release-Zyklen und der Mangel an spezialisierten Fachkräften haben den Ruf nach intelligenteren Automatisierungslösungen lauter werden lassen. Autonome KI-Agenten versprechen, diese Lücke zu schließen, indem sie repetitive Aufgaben übernehmen, Fehler frühzeitig erkennen und sogar bei der Konzeption neuer Features unterstützen. Das bedeutet nicht nur eine Entlastung für Entwicklerteams, sondern auch eine Beschleunigung der Innovationszyklen und eine verbesserte Qualität der Endprodukte. In den kommenden Abschnitten werden wir die Architektur, Anwendungsfälle, Herausforderungen und praktischen Implementierungsschritte dieser faszinierenden Technologie genauer beleuchten.
KERNPUNKT
Autonome KI-Agenten stellen die nächste Evolutionsstufe der Automatisierung dar, indem sie eigenständige Problemlösung, Planung und Adaption ermöglichen. Sie sind entscheidend für die Bewältigung der steigenden Komplexität in der Softwareentwicklung im Jahr 2026.
2. Autonome KI-Agenten im Detail: Architektur und Anwendung
Um das volle Potenzial autonomer KI-Agenten zu verstehen, ist ein Blick auf ihre zugrunde liegende Architektur unerlässlich. Diese Agenten sind typischerweise modular aufgebaut und integrieren verschiedene Komponenten, die ihnen ihre „autonomen“ Fähigkeiten verleihen.
Die Kernkomponenten eines KI-Agenten
Ein typischer autonomer KI-Agent im Jahr 2026 besteht aus mehreren Schlüsselelementen, die zusammenarbeiten, um komplexe Aufgaben zu bewältigen:
1. Speicher (Memory): Dies ist das Gedächtnis des Agenten, das sowohl kurzfristige Kontexte (aktuelle Aufgabe, Zwischenergebnisse) als auch langfristiges Wissen (erlernte Muster, Best Practices, frühere Problemlösungen) speichert. Langfristige Speicher können Vektordatenbanken nutzen, um relevante Informationen schnell abzurufen.
2. Planung (Planning): Die Planungsfunktion zerlegt ein übergeordnetes Ziel in eine Sequenz von kleineren, ausführbaren Schritten. Sie kann auch alternative Pläne erstellen und deren Machbarkeit bewerten. Hierbei kommen oft fortgeschrittene Large Language Models (LLMs) zum Einsatz, die komplexe logische Verbindungen herstellen.
3. Werkzeuge (Tools/Functions): Agenten sind keine isolierten Systeme; sie interagieren mit der Außenwelt über eine Reihe von Werkzeugen. Dies können APIs, Kommandozeilen-Tools, Web-Scraping-Fähigkeiten, Code-Editoren, Compiler oder sogar Datenbankzugriffe sein. Die Fähigkeit, das richtige Werkzeug für die jeweilige Aufgabe auszuwählen und korrekt zu nutzen, ist entscheidend.
4. Reflexion (Reflection/Self-Correction): Nach der Ausführung eines Schritts oder einer Aufgabe bewertet der Agent das Ergebnis. Ist das Ergebnis zufriedenstellend? Gab es Fehler? Wie kann die Strategie für zukünftige ähnliche Aufgaben verbessert werden? Diese Feedback-Schleife ermöglicht es dem Agenten, aus Fehlern zu lernen und seine Leistung kontinuierlich zu optimieren, was ein zentrales Merkmal autonomer Systeme ist.
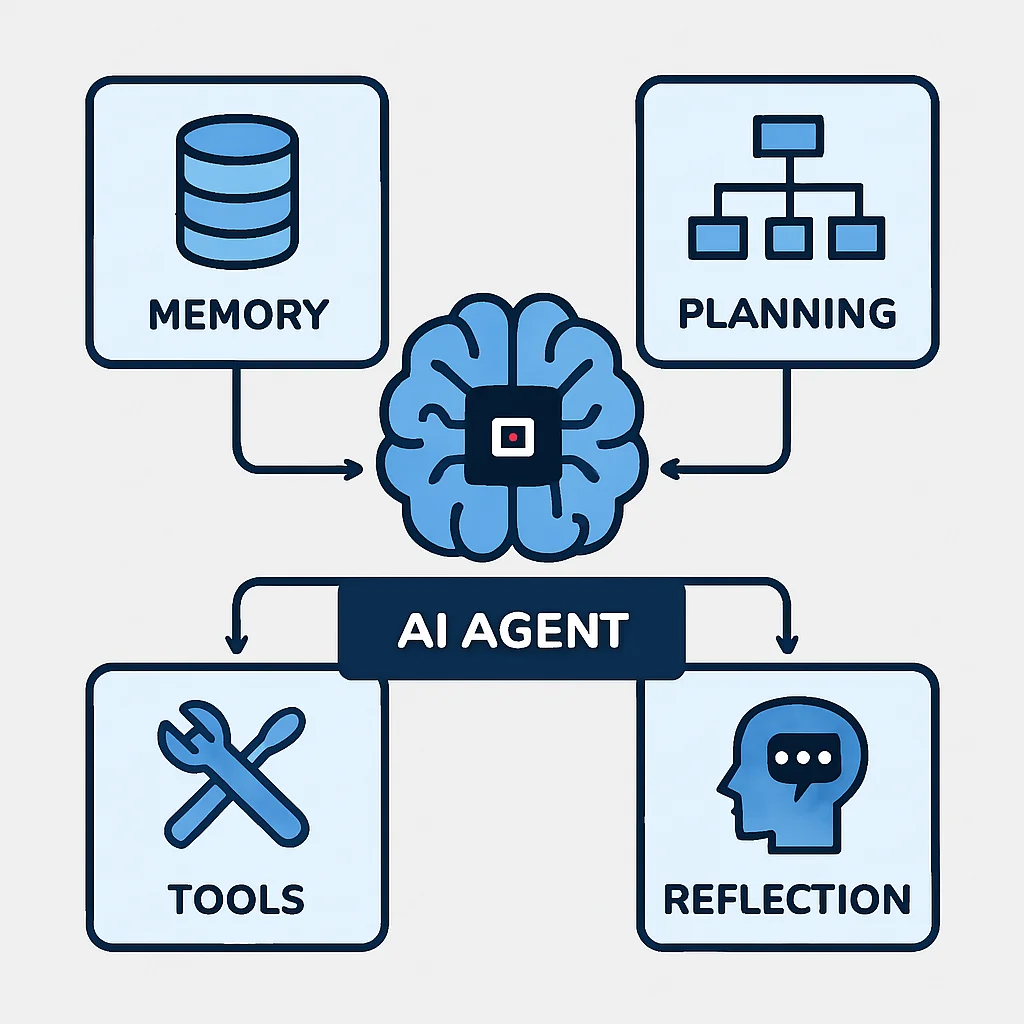
Diese modulare Struktur ermöglicht es, Agenten für eine Vielzahl von Aufgaben zu konfigurieren und zu spezialisieren. Die Interaktion dieser Komponenten bildet einen Kreislauf, der es dem Agenten erlaubt, komplexe, mehrstufige Probleme zu lösen, ohne dass jeder einzelne Schritt von einem menschlichen Bediener vorgegeben werden muss.
Typen von KI-Agenten in der Softwareentwicklung
Im Jahr 2026 sehen wir bereits eine klare Spezialisierung von KI-Agenten, die auf spezifische Bereiche der Softwareentwicklung zugeschnitten sind:
Spezialisierte Agenten-Typen
Code-Generierungs-Agenten — Erstellen von Boilerplate-Code, Implementieren von API-Endpunkten basierend auf Spezifikationen, Refaktorieren bestehenden Codes zur Verbesserung der Wartbarkeit und Performance.
Test- & QA-Agenten — Generieren von umfassenden Testfällen (Unit-, Integrations-, End-to-End-Tests), automatisches Ausführen von Tests, Erkennen von Bugs und Schwachstellen, Erstellen von Fehlerberichten und Vorschlägen zur Behebung.
Deployment- & Operations-Agenten — Automatisches Skalieren von Infrastruktur basierend auf Last, proaktives Erkennen und Beheben von Produktionsproblemen (z.B. Speicherlecks, CPU-Spitzen), Automatisierung von CI/CD-Pipelines.
Datenanalyse-Agenten — Analysieren von Log-Daten zur Erkennung von Anomalien, Optimierung von Datenbankabfragen, Erstellen von Performance-Dashboards und Berichten für Entwickler und Management.
Vergleich: Traditionelle Automatisierung vs. KI-Agenten
Der Hauptunterschied zwischen traditioneller Automatisierung und der Automatisierung durch KI-Agenten liegt in der Intelligenz und Autonomie. Eine vergleichende Tabelle verdeutlicht dies:
| Merkmal | Traditionelle Automatisierung (z.B. Skripte, CI/CD) | Autonome KI-Agenten |
|---|---|---|
| Entscheidungsfindung | Regelbasiert, vordefiniert, deterministisch | Zielorientiert, adaptiv, lernt aus Kontext und Feedback |
| Aufgabenkomplexität | Einfache, repetitive, gut definierte Aufgaben | Komplexe, mehrstufige, dynamische Probleme |
| Lernfähigkeit | Kein eigenständiges Lernen, muss manuell aktualisiert werden | Kontinuierliches Lernen und Selbstoptimierung durch Reflexion |
| Interaktion | Ausführung nach Skript, begrenzte externe Interaktion | Nutzung vielfältiger Tools, APIs und Mensch-Maschine-Interaktion |
| Fehlerbehandlung | Fällt aus oder folgt vordefinierten Fehlerpfaden | Versucht selbstständig, Probleme zu diagnostizieren und zu beheben |
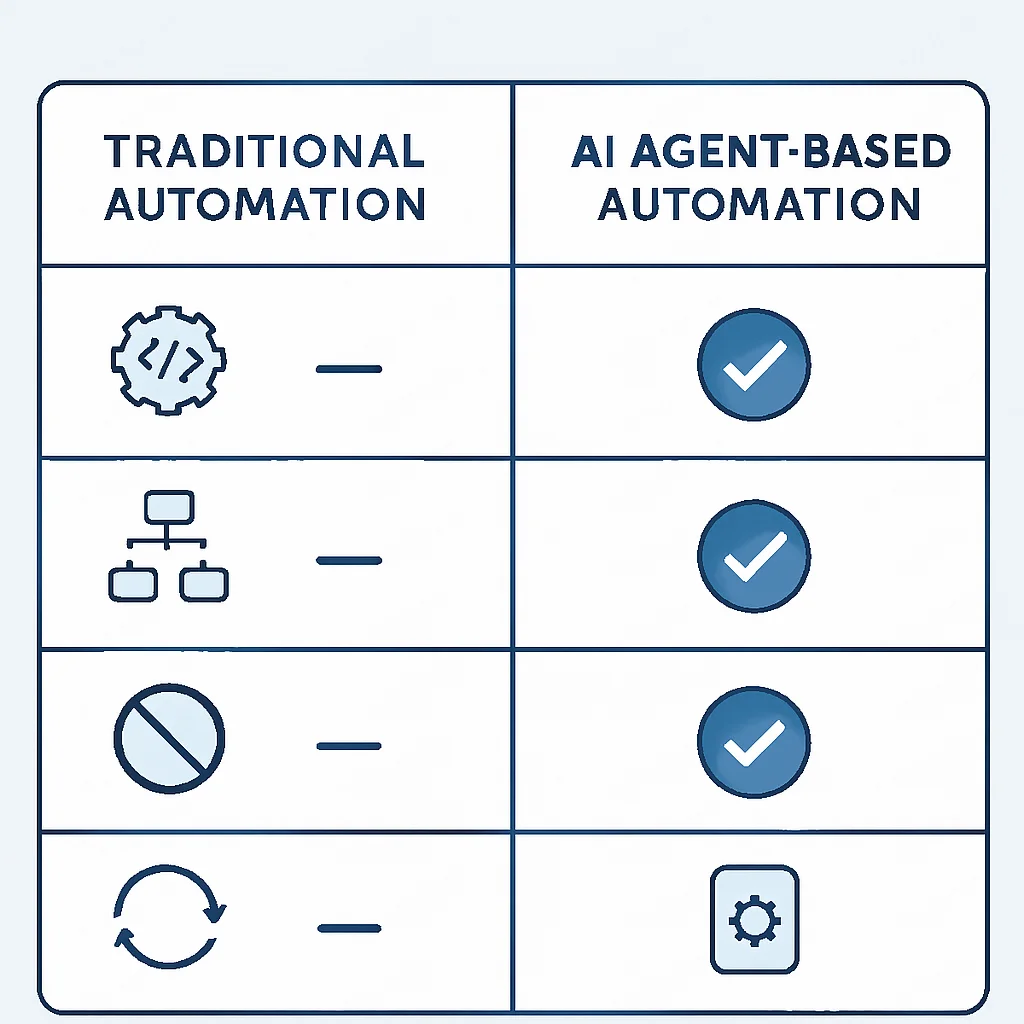
Diese Unterscheidung ist entscheidend. Während traditionelle Automatisierungswerkzeuge weiterhin ihren Platz haben, öffnen KI-Agenten die Tür zu einer neuen Dimension der Effizienz, in der Softwareentwicklung weniger eine Abfolge von manuellen Schritten und mehr ein kollaborativer Prozess zwischen menschlichen Entwicklern und intelligenten, autonomen Systemen wird.
KERNPUNKT
Die modulare Architektur von KI-Agenten, bestehend aus Speicher, Planung, Werkzeugen und Reflexion, ermöglicht es ihnen, komplexe, mehrstufige Aufgaben autonom zu bewältigen und sich dabei kontinuierlich zu verbessern. Dies übertrifft die Fähigkeiten traditioneller, regelbasierter Automatisierungssysteme erheblich.
3. Herausforderungen und Lösungen bei der Implementierung von KI-Agenten
Obwohl das Potenzial autonomer KI-Agenten immens ist, birgt ihre Implementierung und ihr Betrieb auch erhebliche Herausforderungen. Eine vorausschauende Betrachtung dieser Probleme ist entscheidend für eine erfolgreiche Integration in die Softwareentwicklungsprozesse.
Die größten Hürden auf dem Weg zur Agenten-Adoption
1. Nicht-Determinismus und Halluzinationen: KI-Agenten, die auf großen Sprachmodellen (LLMs) basieren, können manchmal ungenaue oder völlig falsche Informationen („Halluzinationen“) generieren oder unvorhersehbare Entscheidungen treffen. Dies ist besonders kritisch in der Softwareentwicklung, wo Präzision und Korrektheit oberste Priorität haben. Ein Agent könnte beispielsweise Code generieren, der logische Fehler enthält oder nicht den Spezifikationen entspricht.
2. Sicherheit und Datenschutz: Autonome Agenten haben oft Zugriff auf sensible Codebasen, Konfigurationsdateien und sogar Produktionssysteme. Ein kompromittierter Agent oder ein fehlerhaft konfigurierter Zugriff kann zu schwerwiegenden Sicherheitslücken oder Datenlecks führen. Die Verwaltung von Berechtigungen und die Isolation von Agenten sind komplexe Aufgaben.
3. Ethische Bedenken und Verantwortlichkeit: Wenn ein Agent autonom Entscheidungen trifft, die negative Konsequenzen haben (z.B. das Löschen kritischer Daten oder das Einführen von Sicherheitslücken), stellt sich die Frage der Verantwortlichkeit. Wer trägt die Schuld? Der Entwickler des Agenten, der Betreiber oder die Organisation, die ihn eingesetzt hat? Zudem können Agenten unbeabsichtigt Bias aus ihren Trainingsdaten übernehmen und in den generierten Lösungen widerspiegeln.
4. Komplexität der Integration: Bestehende Software-Ökosysteme sind oft heterogen und umfassen eine Vielzahl von Tools, Sprachen und Frameworks. Die nahtlose Integration eines KI-Agenten in diese komplexen Umgebungen erfordert erhebliche Anstrengungen und kann zu Kompatibilitätsproblemen führen.
5. Ressourcenverbrauch und Kosten: Der Betrieb von fortschrittlichen KI-Agenten, insbesondere solchen, die rechenintensive LLMs nutzen, kann erhebliche Rechenressourcen und damit hohe Kosten verursachen. Dies ist ein wichtiger Faktor für Unternehmen, die über den Einsatz nachdenken.
PROBLEM 01
Agent generiert unsicheren Code
Ein autonomer Code-Generierungs-Agent erhält die Aufgabe, eine neue Authentifizierungsroutine zu implementieren. Aufgrund unzureichender Spezifikationen oder eines Fehlers in seinem Trainingsmodell generiert der Agent Code, der anfällig für SQL-Injections ist oder schwache Hash-Algorithmen verwendet.
LÖSUNG
Implementierung einer robusten Validierungsschleife mit „Human-in-the-Loop“-Ansatz. Jeder vom Agenten generierte Code muss durch statische Code-Analyse-Tools (SAST) und Peer-Reviews durch menschliche Entwickler geprüft werden, bevor er in die Produktionsumgebung gelangt. Zusätzlich sollte der Agent mit Sicherheitspraktiken trainiert und durch spezifische Prompts zur Einhaltung von Sicherheitsstandards angeleitet werden.
Strategien zur Bewältigung der Herausforderungen
Um die genannten Herausforderungen zu meistern, sind proaktive Maßnahmen und bewährte Verfahren unerlässlich:
1. Robuste Validierung und Feedback-Schleifen: Für die Nicht-Deterministik ist es entscheidend, mehrere Validierungsebenen einzuführen. Dazu gehören automatisierte Tests, Code-Reviews, statische Code-Analyse und eine enge menschliche Überwachung, insbesondere bei kritischen Aufgaben. Agenten sollten so konzipiert sein, dass sie Feedback aktiv einholen und ihre Modelle entsprechend anpassen können.
2. Strikte Zugriffskontrolle und Sandboxing: Agenten sollten immer mit dem Prinzip des geringsten Privilegs betrieben werden, d.h., sie erhalten nur die minimal notwendigen Berechtigungen für ihre Aufgaben. Die Ausführung von Agenten in isolierten Sandbox-Umgebungen kann potenzielle Schäden bei Fehlfunktionen oder Angriffen minimieren. Regelmäßige Sicherheitsaudits und Penetrationstests sind ebenfalls unerlässlich.
3. „Human-in-the-Loop“ (HITL): Für kritische Entscheidungen oder bei Unsicherheit sollte der Agent immer eine menschliche Bestätigung einholen. Dies schafft eine Sicherheitsbarriere und stellt sicher, dass komplexe oder ethisch sensible Entscheidungen nicht ausschließlich von einer KI getroffen werden. Transparenz über die Entscheidungsfindung des Agenten ist hierbei ebenfalls wichtig.
4. Standardisierte APIs und Microservices: Um die Integration zu erleichtern, sollten Agenten so konzipiert werden, dass sie über standardisierte APIs mit bestehenden Systemen kommunizieren können. Eine Microservices-Architektur kann helfen, die Komplexität zu reduzieren und die Agenten modular in das Gesamtsystem einzubetten.
5. Kosten-Nutzen-Analyse und Optimierung: Vor der Implementierung ist eine gründliche Kosten-Nutzen-Analyse erforderlich. Unternehmen sollten mit kleineren, gut definierten Anwendungsfällen beginnen und die Leistung und den Ressourcenverbrauch kontinuierlich überwachen. Die Optimierung der zugrunde liegenden Modelle und der Infrastruktur kann helfen, die Betriebskosten zu senken.
KERNPUNKT
Die erfolgreiche Einführung autonomer KI-Agenten erfordert einen strategischen Ansatz zur Bewältigung von Herausforderungen wie Nicht-Determinismus, Sicherheit und Ethik. Robuste Validierung, „Human-in-the-Loop“-Mechanismen und strikte Zugriffskontrollen sind entscheidend, um Vertrauen und Kontrolle zu gewährleisten.
WARNUNG
Die unkontrollierte oder unzureichend überwachte Implementierung autonomer KI-Agenten kann zu unerwarteten Systemfehlern, Sicherheitslücken und ethischen Dilemmata führen. Eine sorgfältige Planung und Absicherung sind absolut notwendig.
4. Praktische Anwendung: KI-Agenten in der Softwareentwicklung
Nachdem wir die Architektur und die Herausforderungen betrachtet haben, wenden wir uns nun den konkreten Einsatzmöglichkeiten und der Integration autonomer KI-Agenten in den Softwareentwicklungsalltag zu. Im Jahr 2026 sind diese Agenten nicht mehr nur ein Konzept, sondern werden in vielen fortschrittlichen Teams bereits produktiv eingesetzt.
Anwendungsfälle, die den Unterschied machen
Autonome KI-Agenten können Entwickler in einer Vielzahl von Aufgaben unterstützen und so die Produktivität erheblich steigern:
Automatisierte Feature-Entwicklung
Ein Agent erhält eine User Story (z.B. „Als Nutzer möchte ich meine E-Mail-Adresse ändern können“). Er zerlegt diese in technische Aufgaben, generiert den notwendigen Frontend- und Backend-Code, schreibt Datenbank-Migrationen und erstellt sogar die entsprechenden Tests. Der Entwickler prüft und bestätigt die Ergebnisse.
Intelligente Code-Refaktorierung
Ein Agent analysiert eine bestehende Codebasis auf technische Schulden, identifiziert schlecht strukturierte Bereiche oder Performance-Engpässe. Er schlägt dann Refaktorierungsmaßnahmen vor, implementiert diese und stellt sicher, dass alle Tests weiterhin bestanden werden, um die Funktionalität zu erhalten.
Proaktive Fehlerbehebung und Performance-Optimierung
Ein Agent überwacht kontinuierlich Produktionssysteme. Bei der Erkennung von Anomalien (z.B. erhöhte Fehlerraten, langsame Antwortzeiten) diagnostiziert er die Ursache, schlägt Lösungen vor (z.B. Anpassen von Cache-Einstellungen, Optimieren einer Datenbankabfrage) und kann diese bei entsprechender Freigabe sogar automatisch implementieren und deployen.
Schritt-für-Schritt-Integration von KI-Agenten
Die Integration von KI-Agenten in bestehende Entwicklungsprozesse erfordert einen strukturierten Ansatz:
Schritt 1
Aufgabe definieren und isolieren
Beginnen Sie mit einer klar definierten, isolierten Aufgabe, die repetitiv ist und einen messbaren Mehrwert bietet. Zum Beispiel die Generierung von CRUD-Operationen für ein neues Datenmodell oder die Automatisierung von Code-Reviews für bestimmte Qualitätsstandards. Dies minimiert Risiken und erleichtert die Erfolgskontrolle.
Schritt 2
Framework und Tools auswählen
Wählen Sie ein geeignetes Agenten-Framework (z.B. spezialisierte Versionen von LangChain, CrewAI oder proprietäre Lösungen) und integrieren Sie die notwendigen Tools, mit denen der Agent interagieren soll (z.B. Git-Repository, IDE, CI/CD-Pipeline, Jira, Test-Frameworks). Achten Sie auf Kompatibilität und Sicherheitsaspekte.
Schritt 3
Agent konfigurieren und trainieren
Konfigurieren Sie den Agenten mit spezifischen Prompts, die seine Ziele, Beschränkungen und die erwarteten Ausgabeformate definieren. Trainieren Sie den Agenten gegebenenfalls mit unternehmensspezifischen Daten und Best Practices, um seine Genauigkeit und Relevanz zu verbessern. Richten Sie Feedback-Schleifen für die kontinuierliche Verbesserung ein.
Schritt 4
Überwachung und Feinabstimmung
Überwachen Sie die Leistung des Agenten genau. Analysieren Sie seine Ausgaben, Fehler und die benötigte menschliche Interaktion. Nutzen Sie dieses Feedback, um die Konfiguration, die Prompts und möglicherweise das zugrunde liegende Modell des Agenten kontinuierlich zu verfeinern. Iterieren Sie, um die Autonomie und Effizienz schrittweise zu erhöhen.
Beispiel für eine Agenten-Task-Definition (Konzeptuell)
Hier ist ein konzeptionelles Beispiel, wie eine Aufgabe für einen KI-Agenten definiert werden könnte, um eine neue REST-API für ein User-Modell zu erstellen:
CODE-ERKLÄRUNG
Dieses Pseudocode-Beispiel zeigt, wie ein Entwickler eine komplexe Aufgabe für einen Agenten definieren würde. Es umfasst das Ziel, die zu verwendenden Tools, die erwartete Ausgabe und die Validierungsschritte. Es ist ein hochabstrahiertes Beispiel, das die Interaktion mit einem hypothetischen Agenten-Framework darstellt.
# Python Pseudocode für eine Agenten-Task-Definition
from agent_framework import Agent, Task, Tool
# Definition der verfügbaren Tools
git_tool = Tool(name="Git", description="Interagiert mit Git-Repositories", functions=["clone", "commit", "push"])
ide_tool = Tool(name="IDE", description="Bearbeitet und analysiert Code", functions=["edit_file", "run_linter"])
test_tool = Tool(name="TestRunner", description="Führt Unit- und Integrationstests aus", functions=["run_tests", "generate_report"])
db_tool = Tool(name="DatabaseCLI", description="Führt Datenbankmigrationen aus", functions=["migrate"])
# Definition der Hauptaufgabe
api_development_task = Task(
name="Implement User API",
description="Implementiere eine vollständige REST-API für das User-Modell mit CRUD-Operationen. "
"Das Modell sollte Felder für 'id', 'username', 'email' und 'password_hash' enthalten. "
"Sorge für eine sichere Authentifizierung und Validierung.",
goal="Voll funktionsfähige und getestete User-API in der Codebasis",
tools=[git_tool, ide_tool, test_tool, db_tool],
steps=[
"1. Klonen des aktuellen Repositorys.",
"2. Erstellen eines neuen Branches für die Implementierung.",
"3. Generieren des User-Modells und der Datenbankmigration.",
"4. Implementieren der CRUD-Endpunkte (GET, POST, PUT, DELETE) für /api/users.",
"5. Implementieren der Authentifizierungs- und Autorisierungslogik.",
"6. Schreiben von Unit- und Integrationstests für die API.",
"7. Ausführen aller Tests und Sicherstellen, dass sie bestanden werden.",
"8. Durchführen einer statischen Code-Analyse.",
"9. Erstellen eines Pull Requests mit einer Zusammenfassung der Änderungen.",
"10. Warten auf menschliches Review und Feedback."
],
validation_criteria=[
"Alle API-Endpunkte funktionieren korrekt.",
"Sicherheitsstandards (z.B. Passwort-Hashing, Input-Validierung) sind eingehalten.",
"Alle Tests bestanden, Code-Coverage > 80%.",
"Code-Stil und Best Practices sind eingehalten."
]
)
# Initialisierung des Agenten und Zuweisung der Aufgabe
user_api_agent = Agent(
name="API-Entwicklungs-Agent",
role="Entwickelt und testet REST-APIs",
goal="Automatisierte und qualitativ hochwertige API-Implementierung",
tasks=[api_development_task]
)
# Der Agent würde nun beginnen, diese Aufgabe autonom abzuarbeiten,
# die Tools nutzen und bei Bedarf menschliches Feedback einholen.

Dieses Beispiel verdeutlicht, wie übergeordnete Ziele in maschinenlesbare Anweisungen übersetzt werden, die ein Agent dann autonom ausführen kann. Der Entwickler wechselt von der direkten Code-Implementierung zur Orchestrierung und Überwachung intelligenter Agenten.
KERNPUNKT
Die praktische Anwendung von KI-Agenten in der Softwareentwicklung reicht von automatisierter Feature-Entwicklung über Refaktorierung bis hin zur proaktiven Fehlerbehebung. Eine schrittweise Integration, beginnend mit isolierten Aufgaben und einer klaren Definition von Zielen und Tools, ist entscheidend für den Erfolg.
Häufig gestellte Fragen (FAQ)
Q. Was ist der Hauptunterschied zwischen traditioneller Automatisierung und autonomen KI-Agenten?
A. Traditionelle Automatisierung folgt vordefinierten Regeln und Skripten und ist reaktiv. Autonome KI-Agenten hingegen können eigenständig planen, Entscheidungen treffen, aus Erfahrungen lernen und sich an dynamische Gegebenheiten anpassen, um komplexe Ziele zu erreichen.
Q. Welche Risiken bergen autonome KI-Agenten in der Softwareentwicklung?
A. Zu den Hauptrisiken gehören die Generierung von fehlerhaftem oder unsicherem Code (Halluzinationen), Sicherheits- und Datenschutzbedenken durch weitreichende Zugriffsrechte, ethische Fragen bezüglich der Verantwortlichkeit bei Fehlern und der hohe Ressourcenverbrauch.
Q. Wie kann ich als Entwickler mit autonomen KI-Agenten beginnen?
A. Beginnen Sie mit kleinen, klar definierten und isolierten Aufgaben. Nutzen Sie bestehende Agenten-Frameworks, integrieren Sie die benötigten Tools und legen Sie Wert auf robuste Validierungsschleifen sowie menschliche Überprüfung („Human-in-the-Loop“) bei kritischen Schritten.
Q. Werden KI-Agenten menschliche Entwickler ersetzen?
A. Es ist unwahrscheinlich, dass KI-Agenten menschliche Entwickler vollständig ersetzen werden. Vielmehr werden sie als leistungsstarke Assistenten fungieren, die repetitive Aufgaben übernehmen, die Effizienz steigern und Entwicklern ermöglichen, sich auf komplexere, kreativere und strategischere Herausforderungen zu konzentrieren. Die Rolle des Entwicklers wird sich von der reinen Code-Implementierung hin zur Orchestrierung und Feinabstimmung der Agenten entwickeln.
Q. Welche Rolle spielt „Human-in-the-Loop“ bei KI-Agenten?
A. „Human-in-the-Loop“ (HITL) ist eine entscheidende Sicherheits- und Qualitätssicherungsmethode. Sie stellt sicher, dass bei kritischen Entscheidungen oder bei Unsicherheiten des Agenten immer eine menschliche Überprüfung und Bestätigung erfolgt. Dies minimiert Risiken, erhöht die Zuverlässigkeit und gewährleistet ethische Standards im autonomen Betrieb.
Danke fürs Lesen
Die Ära der autonomen KI-Agenten im Jahr 2026 verspricht, die Softwareentwicklung grundlegend zu verändern. Durch ihre Fähigkeit zur eigenständigen Problemlösung, Planung und Adaption können sie Entwicklerteams entlasten, die Effizienz steigern und die Innovationszyklen beschleunigen. Während Herausforderungen wie Sicherheit, Ethik und Nicht-Determinismus sorgfältig gemanagt werden müssen, bieten die Potenziale für eine intelligentere, reaktionsfähigere und produktivere Entwicklungsumgebung enorme Vorteile. Es ist eine spannende Zeit, in der die Zusammenarbeit zwischen Mensch und Maschine eine neue Dimension erreicht.
Fragen? Schreibt es in die Kommentare auf kwonnen.com →