

ZUSAMMENFASSUNG
Die Rolle von Edge Computing in modernen IoT-Architekturen
Eine detaillierte Analyse der Vorteile, Herausforderungen und Implementierungsstrategien von Edge Computing in aktuellen IoT-Systemen.
Keywords: Edge Computing, IoT-Architektur, Datenverarbeitung
EINLEITUNG
1. Hintergrund und Einführung: Warum Edge Computing unverzichtbar wird
Die digitale Transformation hat zu einem exponentiellen Wachstum des Internets der Dinge (IoT) geführt. Milliarden von Geräten, von intelligenten Sensoren in der Industrie bis hin zu vernetzten Fahrzeugen, generieren kontinuierlich riesige Datenmengen. Traditionell wurden diese Daten zur Verarbeitung und Analyse an zentrale Cloud-Rechenzentren gesendet. Doch mit der steigenden Anzahl und der Kritikalität der IoT-Anwendungen stößt dieser zentralisierte Ansatz zunehmend an seine Grenzen.
Edge Computing, also die Verlagerung von Rechenleistung und Datenspeicherung näher an den Ort der Datenerzeugung – die „Edge“ des Netzwerks –, hat sich als eine entscheidende Technologie etabliert, um diese Herausforderungen zu meistern. Es ermöglicht eine schnellere Datenverarbeitung, reduziert die Latenzzeiten, minimiert den Bandbreitenverbrauch und verbessert die Datensicherheit und -privatsphäre. Im Jahr 2026 ist Edge Computing nicht mehr nur ein Trend, sondern eine fundamentale Säule für skalierbare und reaktionsschnelle IoT-Architekturen.
KERNPUNKT
Edge Computing ist die Verlagerung von Datenverarbeitung und -speicherung näher an die IoT-Geräte, um Latenz zu reduzieren, Bandbreite zu sparen und die Sicherheit zu erhöhen. Dies ist im Jahr 2026 für moderne IoT-Systeme unerlässlich.
Die Notwendigkeit für Edge Computing ergibt sich aus mehreren Schlüsselfaktoren. Erstens erfordern viele IoT-Anwendungen Echtzeit-Entscheidungen. Man denke an autonome Fahrzeuge, die innerhalb von Millisekunden auf sich ändernde Straßenbedingungen reagieren müssen, oder an industrielle Automatisierungssysteme, bei denen Verzögerungen zu Produktionsausfällen oder Sicherheitsrisiken führen können. Eine Übertragung aller Daten zur Cloud und zurück würde hier unakzeptable Latenzzeiten verursachen.
Zweitens ist der schiere Umfang der von IoT-Geräten generierten Daten immens. Die Übertragung von Terabytes an Rohdaten über das Netzwerk zu zentralen Cloud-Plattformen ist nicht nur kostspielig, sondern belastet auch die Netzwerkinfrastruktur erheblich. Edge Computing ermöglicht die Vorverarbeitung, Filterung und Aggregation dieser Daten direkt am Entstehungsort, sodass nur relevante oder komprimierte Daten an die Cloud gesendet werden müssen. Dies optimiert die Bandbreitennutzung und senkt die Betriebskosten.
Drittens spielen Datenschutz und Datensicherheit eine immer größere Rolle. Viele sensible Daten, insbesondere in Bereichen wie dem Gesundheitswesen oder der kritischen Infrastruktur, dürfen bestimmte geografische Grenzen nicht verlassen oder müssen strengen Compliance-Vorschriften genügen. Edge Computing bietet die Möglichkeit, diese Daten lokal zu verarbeiten und zu speichern, wodurch die Angriffsfläche reduziert und die Einhaltung regulatorischer Anforderungen erleichtert wird.
KERNANALYSE
2. Kernanalyse: Edge Computing vs. Cloud Computing im IoT
Um die Vorteile von Edge Computing vollständig zu verstehen, ist ein direkter Vergleich mit dem traditionellen Cloud Computing im Kontext von IoT unerlässlich. Beide Ansätze haben ihre Stärken und Schwächen und sind in modernen Architekturen oft komplementär, anstatt sich gegenseitig auszuschließen.
Vergleichstabelle: Edge Computing vs. Cloud Computing
| Merkmal | Edge Computing | Cloud Computing |
|---|---|---|
| Latenz | Extrem niedrig (Millisekunden), ideal für Echtzeitanwendungen. | Höher (Zehner bis Hunderte von Millisekunden), nicht ideal für kritische Echtzeit. |
| Bandbreitennutzung | Reduziert, da nur aggregierte/relevante Daten zur Cloud gesendet werden. | Hoch, da alle Rohdaten zur Cloud übertragen werden müssen. |
| Datensicherheit & Privatsphäre | Verbessert durch lokale Verarbeitung und Speicherung sensibler Daten. | Potenziell höhere Angriffsfläche durch Datenübertragung und zentrale Speicherung. |
| Rechenkapazität | Begrenzt, optimiert für spezifische Aufgaben. | Nahezu unbegrenzt und skalierbar, ideal für komplexe Analysen und Big Data. |
| Kosten | Anschaffungskosten für Hardware am Edge, geringere Betriebskosten für Bandbreite. | Geringe Anschaffungskosten, höhere Betriebskosten für Datenübertragung und Speicherung. |
Diese Tabelle verdeutlicht, dass Edge Computing dort glänzt, wo Echtzeitverarbeitung, Bandbreitenoptimierung und Datensicherheit an vorderster Front stehen. Cloud Computing hingegen ist unschlagbar, wenn es um massive Skalierbarkeit, Speicherung riesiger Datenmengen, komplexe Analysen (z.B. maschinelles Lernen über große Datensätze) und globale Verfügbarkeit geht.
KERNPUNKT
Edge Computing ist ideal für niedrige Latenz und Bandbreitenoptimierung, während Cloud Computing unbegrenzte Skalierbarkeit und komplexe Big-Data-Analysen bietet. Eine hybride Strategie ist oft die effektivste Lösung.
Ein typisches Szenario ist eine hybride Architektur, bei der Edge-Geräte Daten vorverarbeiten und filtern. Kritische Aktionen werden lokal ausgeführt, während aggregierte oder weniger zeitkritische Daten zur weiteren Analyse und Langzeitspeicherung in die Cloud gesendet werden. Zum Beispiel könnte eine Überwachungskamera am Edge Bewegungen erkennen und sofort Alarme auslösen, während die aufgezeichneten Videostreams zur langfristigen Archivierung und für forensische Analysen in die Cloud hochgeladen werden.
Die Entwicklung von Edge-Hardware und -Software im Jahr 2026 hat erhebliche Fortschritte gemacht. Kleinere, energieeffizientere Prozessoren, spezialisiert auf KI-Inferenz am Edge (z.B. NPUs – Neural Processing Units), ermöglichen immer komplexere lokale Verarbeitungsaufgaben. Gleichzeitig bieten Cloud-Anbieter wie AWS (Greengrass), Azure (IoT Edge) und Google Cloud (Anthos for Edge) integrierte Lösungen an, die die nahtlose Verwaltung und Bereitstellung von Anwendungen zwischen Cloud und Edge erleichtern.
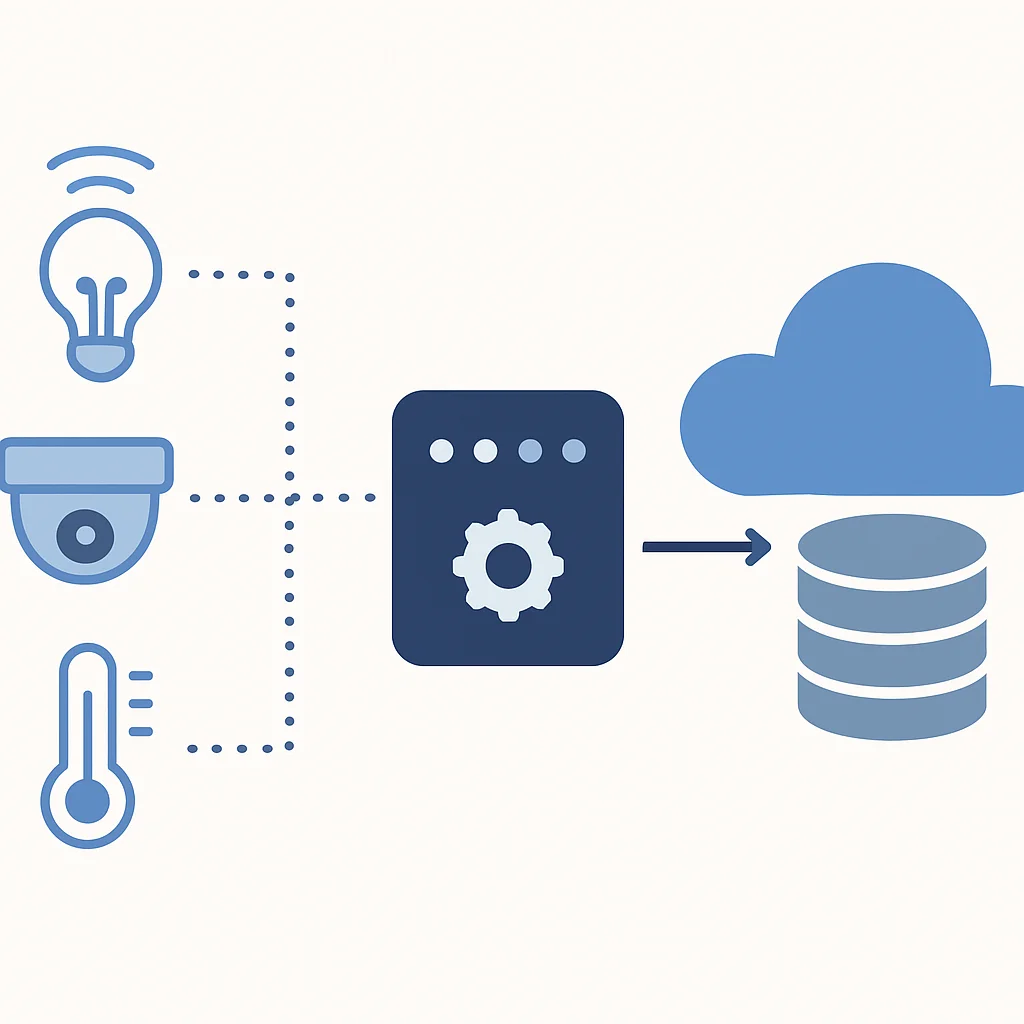
Dieses Architekturmodell maximiert die Vorteile beider Welten: die Agilität und Reaktionsfähigkeit des Edge und die Skalierbarkeit und Rechenleistung der Cloud. Die Herausforderung besteht darin, die richtige Balance zu finden und die Workloads intelligent zwischen Edge und Cloud zu verteilen, basierend auf den spezifischen Anforderungen der Anwendung.
PROBLEMLÖSUNG
3. Technische Herausforderungen und Lösungsansätze im Edge IoT
Obwohl Edge Computing enorme Vorteile bietet, bringt es auch eine Reihe von technischen Herausforderungen mit sich. Diese müssen proaktiv angegangen werden, um eine robuste und effiziente IoT-Lösung zu gewährleisten.
KERNPUNKT
Herausforderungen im Edge Computing umfassen Ressourcenbeschränkungen, instabile Netzwerkkonnektivität und komplexe Sicherheitsverwaltung. Lösungen liegen in Softwareoptimierung, Offline-Fähigkeit und zentralisierten Orchestrierungsplattformen.
Die kontinuierliche Weiterentwicklung von Edge-Betriebssystemen (z.B. Yocto Linux, FreeRTOS), Container-Runtimes (z.B. containerd, K3s) und Management-Tools ist entscheidend, um diese Herausforderungen zu bewältigen. Im Jahr 2026 sehen wir eine zunehmende Standardisierung und Integration von Edge-Lösungen in bestehende Cloud-Ökosysteme, was die Komplexität für Entwickler und Betreiber erheblich reduziert.
ANWENDUNG
4. Praktische Implementierung: Ein Referenzarchitektur-Beispiel
Um die Konzepte greifbarer zu machen, betrachten wir eine Referenzarchitektur für ein intelligentes Fabriksystem, das Edge Computing nutzt, um die Effizienz zu steigern und Ausfallzeiten zu minimieren.
Anwendungsfall: Predictive Maintenance in der Industrie 4.0
In einer modernen Fabrik sind zahlreiche Maschinen mit Sensoren ausgestattet, die Vibrationsdaten, Temperatur, Druck und andere Betriebsparameter erfassen. Ziel ist es, den Zustand der Maschinen in Echtzeit zu überwachen, potenzielle Ausfälle frühzeitig zu erkennen (Predictive Maintenance) und Wartungsarbeiten proaktiv zu planen.
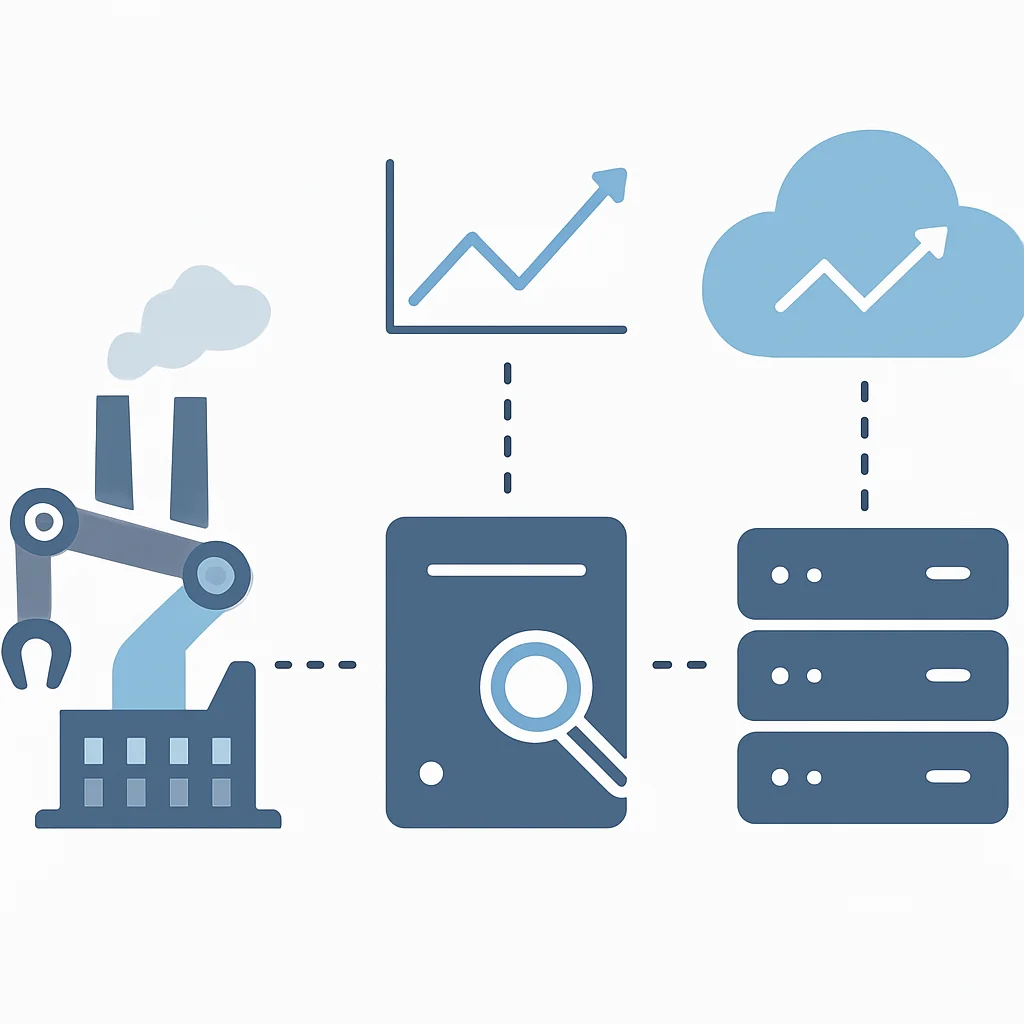
Architekturkomponenten und Datenfluss
KERNPUNKT
Ein intelligentes Fabriksystem nutzt Edge Computing für Echtzeit-Anomalieerkennung und sofortige Aktionen, während die Cloud für umfassende Langzeitanalysen, Modelltraining und globale Optimierung eingesetzt wird. Dies ermöglicht eine effiziente Predictive Maintenance.
Dieses Beispiel zeigt, wie Edge Computing nicht nur die Reaktionsfähigkeit von IoT-Systemen verbessert, sondern auch die Datenverarbeitungskette effizienter gestaltet und die Gesamtbetriebskosten senkt, indem es Bandbreite und Cloud-Ressourcen schont. Die Fähigkeit, kritische Entscheidungen lokal und in Echtzeit zu treffen, ist der Schlüssel zu den Vorteilen von Edge Computing in der Industrie 4.0 und darüber hinaus.
Häufig gestellte Fragen (FAQ)
Q. Was ist der Hauptvorteil von Edge Computing gegenüber Cloud Computing im IoT?
Der Hauptvorteil von Edge Computing ist die drastische Reduzierung der Latenz, da Daten näher am Entstehungsort verarbeitet werden. Dies ist entscheidend für Echtzeitanwendungen wie autonome Systeme oder industrielle Steuerungen, wo Millisekunden über den Erfolg einer Aktion entscheiden können.
Q. Welche Arten von Daten werden typischerweise am Edge verarbeitet und welche in der Cloud?
Am Edge werden oft Rohdaten gefiltert, vorverarbeitet und für schnelle, lokale Entscheidungen analysiert. Kritische Alarme und aggregierte Daten werden dann an die Cloud gesendet, wo komplexe Analysen, langfristige Trend-Identifizierung, Modelltraining für maschinelles Lernen und die globale Datenarchivierung stattfinden.
Q. Welche Sicherheitsbedenken gibt es bei Edge Computing und wie werden sie angegangen?
Sicherheitsbedenken umfassen den Schutz verteilter Edge-Geräte vor physischen Angriffen, die Sicherstellung von Over-the-Air-Updates und die Einhaltung von Datenschutzbestimmungen. Angesprochen werden diese durch Zero-Trust-Architekturen, hardwarebasierte Sicherheitsmodule, sichere Boot-Verfahren und Ende-zu-Ende-Verschlüsselung sowie zentrale Managementplattformen.
Q. Kann Edge Computing Cloud Computing vollständig ersetzen?
Nein, Edge Computing kann Cloud Computing in den meisten Szenarien nicht vollständig ersetzen. Stattdessen sind sie komplementäre Technologien. Edge Computing optimiert die lokale Verarbeitung und Latenz, während Cloud Computing unbegrenzte Skalierbarkeit, Speicherkapazität und Rechenleistung für globale Analysen und Langzeitarchivierung bietet. Eine hybride Architektur ist oft die effektivste Lösung.
Danke fürs Lesen!
Edge Computing ist eine transformative Technologie, die die Art und Weise, wie wir IoT-Systeme entwerfen und betreiben, grundlegend verändert. Es ermöglicht neue Anwendungsfälle, die zuvor aufgrund von Latenz, Bandbreite oder Sicherheitsbedenken undenkbar waren.
Die Integration von Edge- und Cloud-Ressourcen wird im Jahr 2026 weiterhin das Rückgrat innovativer IoT-Lösungen bilden. Wir hoffen, dieser Bericht hat Ihnen einen umfassenden Einblick in dieses spannende Feld gegeben. Fragen? Schreibt es in die Kommentare!
Verwandte Artikel
- [Tools & Produktivität] API-Testing-Tools 2026: Postman, Insomnia und Hoppscotch im Vergleich für Entwickler
- [Tools & Produktivität] Die besten Terminal-Tools für Entwickler 2026: Effizienter arbeiten mit der Kommandozeile
- [Tools & Produktivität] Die besten Browser-Extensions für Entwickler 2026: Produktivität und Workflow optimieren