

ZUSAMMENFASSUNG
KI-gestützte Code-Generierung: Eine Analyse der Auswirkungen auf die Softwareentwicklung 2026
Dieser Bericht analysiert die tiefgreifenden Veränderungen, die KI-gestützte Code-Generierung im Jahr 2026 in der Softwareentwicklung mit sich bringt, und beleuchtet deren Chancen und Herausforderungen.
Keywords: KI-Code-Generierung, Softwareentwicklung 2026, Entwicklerproduktivität
INHALTSVERZEICHNIS
1. Hintergrund und Bedeutung der KI-Code-Generierung
2. Kernanalyse: Architekturen und Modelle
3. Herausforderungen und Lösungsansätze
4. Praktische Anwendung: Implementierungsstrategien
5. Ausblick und Fazit
6. Häufig gestellte Fragen (FAQ)
1. Hintergrund und Bedeutung der KI-Code-Generierung
Die Softwareentwicklung durchläuft im Jahr 2026 eine transformative Phase, die maßgeblich durch den Aufstieg der künstlichen Intelligenz, insbesondere im Bereich der Code-Generierung, geprägt ist. Was vor wenigen Jahren noch als futuristisches Konzept galt, ist heute eine etablierte Realität in vielen Entwicklungsteams weltweit. KI-Tools, die in der Lage sind, Code-Snippets, ganze Funktionen oder sogar komplexe Architekturen vorzuschlagen und zu generieren, revolutionieren die Art und Weise, wie Entwickler arbeiten, und versprechen eine signifikante Steigerung der Produktivität und Effizienz.
Historisch gesehen war die Code-Erstellung ein rein manueller, zeitaufwendiger Prozess, der tiefgreifendes Fachwissen und sorgfältige Detailarbeit erforderte. Mit dem Fortschritt in den Bereichen maschinelles Lernen und großen Sprachmodellen (LLMs) haben sich jedoch neue Möglichkeiten eröffnet. Diese Modelle sind in der Lage, aus riesigen Mengen bestehenden Codes zu lernen und Muster zu erkennen, um dann auf Basis von natürlichsprachlichen Beschreibungen oder Kontextinformationen neuen Code zu erzeugen. Dies reicht von der Autovervollständigung in der IDE bis hin zur Generierung von Boilerplate-Code, Datenbank-Schema-Definitionen oder sogar der Übersetzung von Code zwischen verschiedenen Programmiersprachen.
Die Bedeutung dieser Entwicklung kann kaum überschätzt werden. Studien des Branchenanalysten Gartner prognostizieren, dass bis Ende 2026 über 40% des neuen Anwendungscodes zumindest teilweise durch KI generiert wird – ein massiver Anstieg gegenüber weniger als 5% im Jahr 2023. Diese Technologie ist nicht nur ein „nice-to-have“, sondern wird zunehmend zu einem entscheidenden Wettbewerbsfaktor. Unternehmen, die KI-gestützte Code-Generierung effektiv in ihre Workflows integrieren, können Entwicklungszyklen verkürzen, Fehlerquoten reduzieren und Entwickler für komplexere, strategischere Aufgaben freisetzen. Dies führt zu einer höheren Innovationsgeschwindigkeit und einer besseren Anpassungsfähigkeit an Marktanforderungen.
Die vorliegende Analyse beleuchtet die aktuellen Architekturen und Modelle, die Herausforderungen und die praktischen Implementierungsstrategien, um ein umfassendes Bild der KI-gestützten Code-Generierung im Jahr 2026 zu zeichnen und Entwicklern sowie Entscheidungsträgern wertvolle Einblicke zu bieten.
KERNPUNKT
KI-gestützte Code-Generierung ist im Jahr 2026 ein zentraler Treiber für Produktivitätssteigerung und Innovationsfähigkeit in der Softwareentwicklung. Sie verändert die Rolle des Entwicklers von einem reinen Code-Schreiber zu einem Architekten und Integrator.
2. Kernanalyse: Architekturen und Modelle
Die Leistungsfähigkeit der KI-gestützten Code-Generierung beruht auf hochentwickelten Architekturen und Modellen, die kontinuierlich weiterentwickelt werden. Im Jahr 2026 dominieren primär zwei Ansätze: große Sprachmodelle (LLMs) und spezialisierte Modelle, oft in Kombination mit Retrieval-Augmented Generation (RAG).
2.1 Große Sprachmodelle (LLMs) als Basis
Die meisten führenden Code-Generierungs-Tools wie GitHub Copilot X (basierend auf OpenAI’s GPT-4.5) oder Amazon CodeWhisperer (mit eigenem optimierten Modell) nutzen die zugrunde liegende Architektur von LLMs. Diese Modelle sind auf Petabytes von Text- und Code-Daten trainiert und zeichnen sich durch ihre Fähigkeit aus, Kontext zu verstehen und kohärenten, syntaktisch korrekten Code in verschiedenen Programmiersprachen zu generieren. Ihre Stärke liegt in der breiten Anwendbarkeit und der Fähigkeit, auch auf vage Anweisungen hin sinnvolle Vorschläge zu liefern.
Ein Schlüsselelement ist die Transformer-Architektur, die es LLMs ermöglicht, Abhängigkeiten über lange Text- und Code-Sequenzen hinweg zu erfassen. Für Code-Generierung werden diese Modelle oft speziell auf Code-Datensätzen (z.B. öffentliche GitHub-Repositories) feinabgestimmt, um ihre Leistung für Programmieraufgaben zu optimieren. Das Ergebnis sind Modelle, die nicht nur Code generieren, sondern auch Fehler finden, Refactorings vorschlagen und Dokumentationen erstellen können.
2.2 Spezialisierte Modelle und RAG-Ansätze
Neben den breit aufgestellten LLMs gewinnen spezialisierte Modelle an Bedeutung, die für bestimmte Domänen, Programmiersprachen oder Aufgaben optimiert sind. Diese Modelle sind oft kleiner, effizienter und können präzisere Ergebnisse in ihrem spezifischen Bereich liefern. Beispiele hierfür sind Modelle, die speziell für die Generierung von SQL-Abfragen, UI-Komponenten in React oder Infrastruktur-as-Code (IaC) in Terraform trainiert wurden.
Ein weiterer wichtiger Trend ist die Kombination von LLMs mit Retrieval-Augmented Generation (RAG). Hierbei wird das LLM nicht nur mit seinem internen Wissen betrieben, sondern kann zusätzlich auf externe, aktuelle oder unternehmensspezifische Wissensdatenbanken zugreifen. Bevor Code generiert wird, durchsucht ein Retrieval-System relevante Dokumente (z.B. interne Wikis, API-Dokumentationen, Best Practices des Unternehmens) und stellt diese dem LLM als zusätzlichen Kontext zur Verfügung. Dies verbessert die Genauigkeit, Relevanz und Sicherheit des generierten Codes erheblich, da das Modell auf verifizierte und aktuelle Informationen zugreifen kann, anstatt nur auf sein zum Trainingszeitpunkt vorhandenes Wissen angewiesen zu sein.
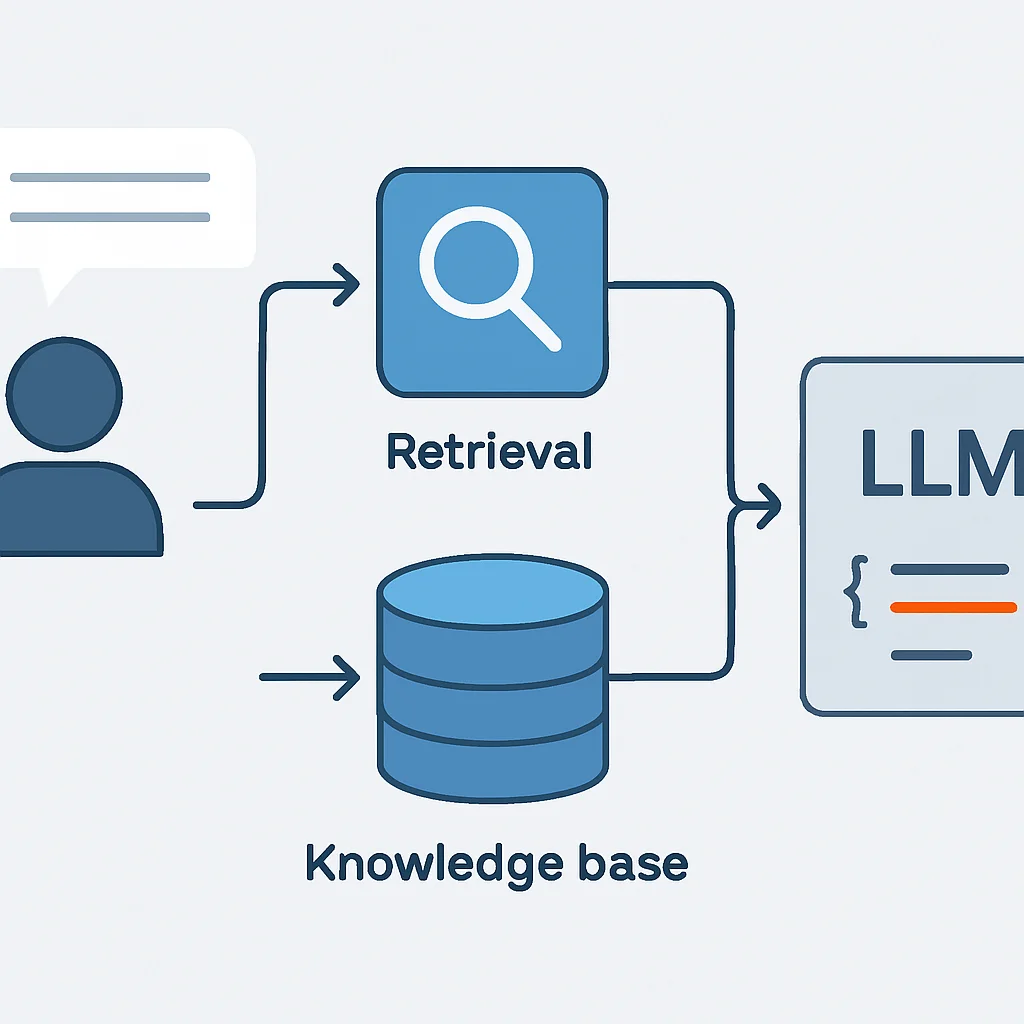
2.3 Integration in Entwicklungsumgebungen
Die praktische Anwendung dieser Modelle erfolgt meist über Plugins für Integrierte Entwicklungsumgebungen (IDEs) wie VS Code, IntelliJ IDEA oder Visual Studio. Diese Plugins agieren als Schnittstelle zwischen dem Entwickler und dem KI-Modell. Sie senden den aktuellen Code-Kontext (den Code, an dem der Entwickler gerade arbeitet, umliegende Dateien, Kommentare) an das KI-Backend und empfangen Code-Vorschläge, die direkt in die IDE integriert werden können.
Darüber hinaus gibt es dedizierte Plattformen, die über die reine Code-Generierung hinausgehen und Funktionen für Code-Review, Testfallgenerierung und automatische Dokumentation bieten. Diese Plattformen werden oft als „AI-powered Developer Platforms“ bezeichnet und zielen darauf ab, den gesamten Softwareentwicklungslebenszyklus (SDLC) zu optimieren.
Vergleich führender KI-Code-Generatoren (2026)
GitHub Copilot X — Basierend auf GPT-4.5, breite Sprachunterstützung, tiefe IDE-Integration, Fokus auf Autovervollständigung und Funktionsgenerierung. Stärken: Kontextverständnis, hohe Akzeptanz. Schwächen: Lizenzkosten, potenzielle Urheberrechtsfragen.
Amazon CodeWhisperer — Eigenes, auf Amazon-Daten trainiertes Modell, starke Integration in AWS-Services, Sicherheits-Scans, Lizenzprüfung. Stärken: Fokus auf Sicherheit und Compliance, AWS-Integration. Schwächen: Weniger breit aufgestellt als Copilot.
Google Gemini Code — Teil des Gemini-Ökosystems, Integration in Google Cloud und Android Studio, starke Fähigkeiten in Python, Java, Go. Stärken: Multi-Modalität, Google-Ökosystem-Integration. Schwächen: Noch relativ jung im Vergleich zu etablierten Playern.
Custom Enterprise LLMs — Von Unternehmen selbst trainierte oder feinabgestimmte Modelle auf internen Codebasen. Stärken: Höchste Relevanz für spezifische Unternehmensdomänen, vollständige Datenhoheit. Schwächen: Hoher Implementierungs- und Wartungsaufwand.
3. Herausforderungen und Lösungsansätze
Obwohl die KI-gestützte Code-Generierung enorme Vorteile bietet, bringt sie auch eine Reihe signifikanter Herausforderungen mit sich. Eine fundierte Auseinandersetzung mit diesen Problemen und die Entwicklung geeigneter Lösungsansätze sind entscheidend für eine erfolgreiche Adoption und nachhaltige Nutzung.
3.1 Problem: Code-Qualität und -Sicherheit
Eines der größten Bedenken ist die Qualität und Sicherheit des generierten Codes. KI-Modelle können Fehler machen, veraltete Muster verwenden oder sogar Sicherheitslücken einführen, insbesondere wenn sie auf fehlerhaften oder unsicheren Daten trainiert wurden. Dies kann zu schwer wartbarem Code, unerwartetem Verhalten oder kritischen Schwachstellen führen.
PROBLEM 01
Inkonsistente Code-Qualität und potenzielle Sicherheitslücken
KI-generierter Code kann von unterschiedlicher Qualität sein, Best Practices ignorieren und unbeabsichtigt Sicherheitsrisiken einführen, was den manuellen Review-Aufwand erhöht und das Risiko von Produktionsfehlern birgt.
LÖSUNG
Erweiterte Statische Code-Analyse und KI-gestütztes Testing: Integration von spezialisierten Tools zur statischen Code-Analyse (SAST) und dynamischen Anwendungssicherheitstests (DAST), die speziell für KI-generierten Code optimiert sind. Ergänzend dazu können KI-Modelle eingesetzt werden, um Testfälle zu generieren und potenzielle Fehler frühzeitig zu erkennen. Menschliche Code-Reviews bleiben unerlässlich, werden jedoch durch diese Tools effizienter gestaltet.
3.2 Problem: Lizenzierung und Urheberrecht
KI-Modelle werden auf großen Mengen von Open-Source-Code trainiert, der oft unter verschiedenen Lizenzen steht. Dies wirft komplexe Fragen bezüglich der Lizenzierung des generierten Codes und potenzieller Urheberrechtsverletzungen auf. Unternehmen sind besorgt, dass sie unwissentlich Code verwenden könnten, der Lizenzverpflichtungen mit sich bringt oder sogar gegen Urheberrechte verstößt.
Lösungsansatz: Klare Unternehmensrichtlinien für die Nutzung von KI-generiertem Code sind entscheidend. Viele KI-Tools bieten mittlerweile Funktionen zur Lizenzprüfung an, die erkennen, ob generierter Code aus spezifischen lizenzierten Quellen stammt. Zudem sollten Entwickler geschult werden, generierten Code kritisch zu prüfen und bei Unsicherheiten alternative Implementierungen zu bevorzugen. Eine transparente Attributionspolitik und die Förderung von Open-Source-Beiträgen können ebenfalls zur Lösung beitragen.
KERNPUNKT
Die juristischen Implikationen von KI-generiertem Code, insbesondere Urheberrechts- und Lizenzfragen, erfordern proaktive Maßnahmen wie interne Richtlinien, Lizenz-Scanning-Tools und eine Kultur der kritischen Code-Prüfung.
3.3 Problem: Integration in CI/CD-Pipelines
Die nahtlose Integration von KI-Code-Generierung in bestehende Continuous Integration/Continuous Deployment (CI/CD)-Pipelines ist eine technische Herausforderung. Wie können generierte Code-Vorschläge automatisch in den Build-Prozess integriert, getestet und bereitgestellt werden, ohne die Stabilität oder Sicherheit der Pipeline zu gefährden?
Lösungsansatz: Die Entwicklung „AI-aware“ CI/CD-Pipelines, die spezielle Schritte für KI-generierten Code enthalten. Dies könnte die automatische Ausführung von Code-Scans, die Generierung von Unit-Tests durch KI und die Einbindung von menschlichen Freigabeschleifen für kritische Code-Abschnitte umfassen. Die Automatisierung muss dabei so gestaltet sein, dass sie die Vorteile der KI-Geschwindigkeit nutzt, aber gleichzeitig die notwendigen Qualitätssicherungs- und Governance-Prozesse beibehält.
4. Praktische Anwendung: Implementierungsstrategien
Die erfolgreiche Integration von KI-gestützter Code-Generierung erfordert mehr als nur die Installation eines IDE-Plugins. Es bedarf einer strategischen Herangehensweise, die technische, prozessuale und kulturelle Aspekte berücksichtigt. Im Folgenden werden bewährte Strategien und ein konkretes Anwendungsbeispiel vorgestellt.
4.1 Schritt-für-Schritt-Integration in den Entwickler-Workflow
Schritt 1
Pilotprojekt und Tool-Auswahl
Beginnen Sie mit einem kleinen Team und einem nicht-kritischen Projekt. Evaluieren Sie verschiedene KI-Code-Generatoren basierend auf Sprachunterstützung, Integration in Ihre IDEs und spezifischen Anwendungsfällen. Sammeln Sie Feedback von Entwicklern.
Schritt 2
Schulung und Best Practices
Schulen Sie Entwickler im effektiven Umgang mit den KI-Tools. Betonen Sie die Wichtigkeit der Code-Prüfung, des Verständnisses des generierten Codes und der Anpassung an interne Coding-Standards. Etablieren Sie Richtlinien für die Nutzung, insbesondere im Hinblick auf Sicherheit und Lizenzierung.
Schritt 3
Integration in CI/CD und Governance
Integrieren Sie automatisierte Code-Scans (Statische Analyse, Linting) in Ihre CI/CD-Pipeline, um die Qualität und Sicherheit des generierten Codes zu gewährleisten. Implementieren Sie Governance-Mechanismen, die sicherstellen, dass generierter Code den Unternehmensrichtlinien entspricht und bei Bedarf menschlich geprüft wird.
Schritt 4
Monitoring und kontinuierliche Optimierung
Überwachen Sie die Auswirkungen der KI-Nutzung auf Metriken wie Entwicklungsgeschwindigkeit, Fehlerquoten und Code-Qualität. Sammeln Sie kontinuierlich Feedback und passen Sie Strategien und Tool-Konfigurationen an, um die Effektivität zu maximieren.
KERNPUNKT
Eine schrittweise Implementierung, beginnend mit Pilotprojekten und umfassenden Schulungen, ist entscheidend für die erfolgreiche Einführung von KI-Code-Generierung in der Softwareentwicklung.
4.2 Anwendungsbeispiel: Generierung einer REST-API-Funktion
Stellen wir uns vor, ein Entwickler soll eine neue REST-API-Funktion in Python (mit FastAPI) erstellen, die Benutzerdaten aus einer Datenbank abruft. Anstatt alles manuell zu schreiben, kann die KI unterstützen.
Anwendungsfall: FastAPI Benutzer-Endpoint
Ein Entwickler benötigt einen FastAPI-Endpoint, der Benutzerinformationen anhand einer ID aus einer PostgreSQL-Datenbank abruft.
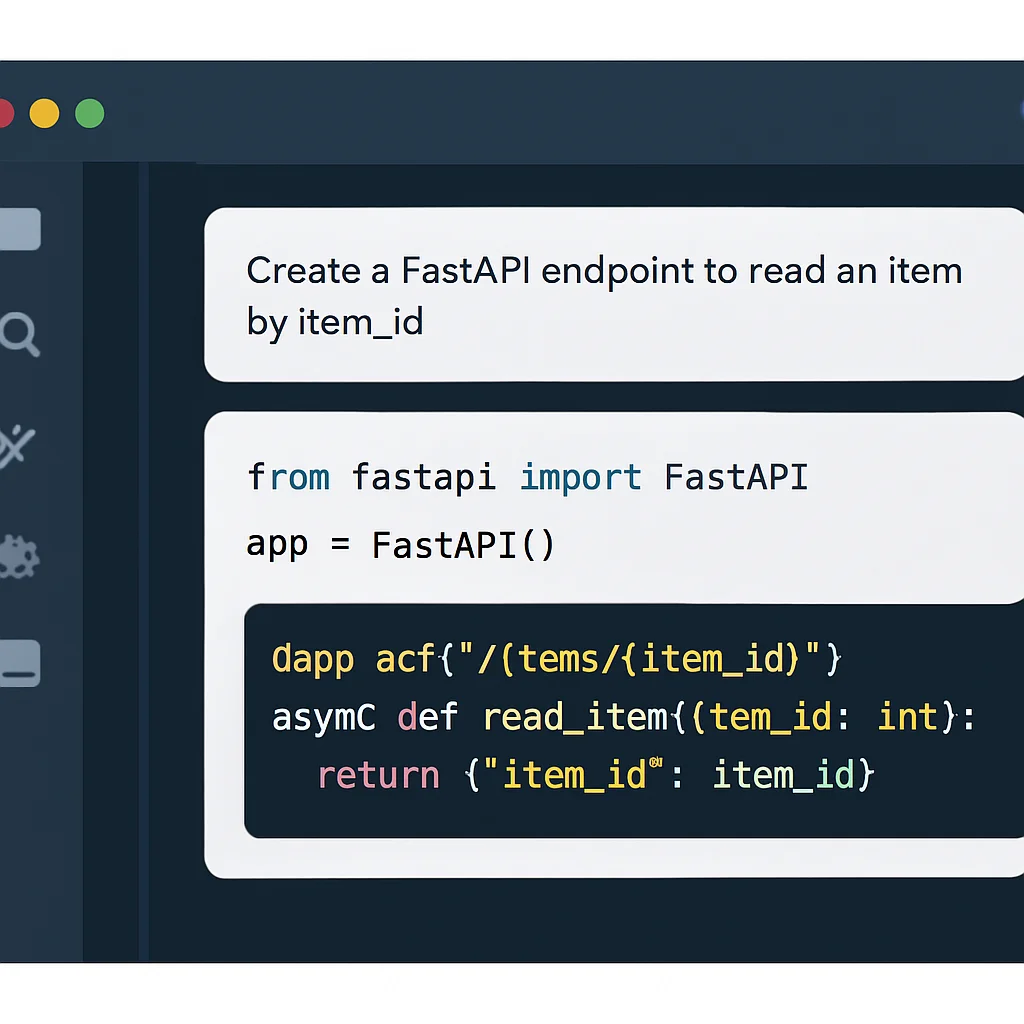
Der Entwickler gibt in der IDE einen Kommentar ein wie: # FastAPI endpoint to get user by ID from a PostgreSQL database. Das KI-Tool analysiert den Kontext (vorhandene Datenbankverbindung, FastAPI-Setup) und schlägt folgenden Code vor:
CODE-ERKLÄRUNG
Dieser Python-Code zeigt einen FastAPI-Endpoint, der über eine Datenbankverbindung (Dependency Injection) einen Benutzer anhand seiner ID aus einer PostgreSQL-Datenbank abruft. Er verwendet ein Pydantic-Modell zur Datenvalidierung und gibt einen 404-Fehler zurück, wenn der Benutzer nicht gefunden wird.
from fastapi import FastAPI, Depends, HTTPException
from pydantic import BaseModel
from typing import Optional
# Annahme: Eine Datenbank-Session-Dependency ist bereits definiert
# Beispiel:
# from sqlalchemy.orm import Session
# from database import get_db, User as DBUser
app = FastAPI()
class User(BaseModel):
id: int
name: str
email: str
is_active: bool
# Dummy-Datenbankfunktion für dieses Beispiel
async def get_user_from_db(user_id: int):
# In einer echten Anwendung würde hier eine Datenbankabfrage erfolgen
# z.B. user = db.query(DBUser).filter(DBUser.id == user_id).first()
await asyncio.sleep(0.1) # Simuliert Datenbank-Latenz
if user_id == 1:
return {"id": 1, "name": "Alice", "email": "[email protected]", "is_active": True}
elif user_id == 2:
return {"id": 2, "name": "Bob", "email": "[email protected]", "is_active": False}
return None
@app.get("/users/{user_id}", response_model=User)
async def read_user(user_id: int): # , db: Session = Depends(get_db)
user_data = await get_user_from_db(user_id)
if user_data is None:
raise HTTPException(status_code=404, detail="User not found")
return User(**user_data)
# Um diesen Code lokal zu testen (benötigt `uvicorn`):
# uvicorn your_module_name:app --reload
# Gehen Sie zu http://127.0.0.1:8000/users/1
Dieser Code-Vorschlag ist nicht nur syntaktisch korrekt, sondern berücksichtigt auch Best Practices wie Pydantic-Modelle für die Response-Validierung und die Behandlung von „Not Found“-Fällen. Der Entwickler kann diesen Vorschlag schnell anpassen, beispielsweise um eine echte Datenbank-Session zu integrieren, und spart so wertvolle Zeit beim Schreiben des Boilerplate-Codes.
5. Ausblick und Fazit
Die KI-gestützte Code-Generierung hat im Jahr 2026 ihren Status als Nischentechnologie längst hinter sich gelassen und ist zu einem integralen Bestandteil der modernen Softwareentwicklung geworden. Sie hat das Potenzial, die Produktivität von Entwicklern erheblich zu steigern, die Time-to-Market zu verkürzen und die Innovation voranzutreiben.
Die Zukunft hält weitere spannende Entwicklungen bereit. Wir werden eine noch tiefere Integration von KI in den gesamten Softwareentwicklungslebenszyklus erleben, von der Anforderungsanalyse (KI-generierte User Stories) über das Design (KI-generierte Architekturvorschläge) bis hin zur Wartung (KI-gestützte Fehlerbehebung und Refactoring). Multi-modale KI-Modelle, die nicht nur Text, sondern auch Diagramme, UI-Mockups oder sogar Audio-Eingaben verarbeiten können, werden die Interaktion mit Code-Generatoren revolutionieren. Die Fähigkeit von KI, aus unternehmensspezifischen Codebasen zu lernen und sich an individuelle Coding-Standards anzupassen, wird weiter verfeinert, was zu noch relevanteren und qualitativ hochwertigeren Vorschlägen führt.
Vorteile
✓ Erhöhte Entwicklerproduktivität durch schnellere Code-Erstellung.
✓ Reduzierung von Boilerplate-Code und repetitiven Aufgaben.
✓ Verbesserte Code-Konsistenz und Einhaltung von Best Practices.
✓ Ermöglicht Entwicklern, sich auf komplexere Design- und Architekturprobleme zu konzentrieren.
✓ Schnellere Prototyping- und Experimentierphasen.
Nachteile
✗ Potenzielle Einführung von Bugs oder Sicherheitslücken im generierten Code.
✗ Unklare Lizenz- und Urheberrechtsfragen bei der Verwendung von Trainingsdaten.
✗ Gefahr der Abhängigkeit von KI-Tools und Verlust von grundlegenden Programmierkenntnissen.
✗ Erhöhter Bedarf an kritischer Code-Review und Validierung.
✗ Hoher Rechenaufwand und Energieverbrauch für große KI-Modelle.
KERNPUNKT
Die evolutionäre Entwicklung der KI-Code-Generierung erfordert von Entwicklern und Unternehmen eine kontinuierliche Anpassung, um ihre Vorteile voll auszuschöpfen und gleichzeitig Risiken wie Code-Qualität, Sicherheit und Lizenzierung proaktiv zu managen.
Es ist jedoch entscheidend, die menschliche Komponente nicht zu vernachlässigen. Entwickler werden nicht ersetzt, sondern ihre Rolle wandelt sich. Sie werden zu „KI-Kuratoren“, die generierten Code kritisch prüfen, anpassen und optimieren. Das Verständnis von Softwarearchitektur, Design-Patterns und Clean Code bleibt wichtiger denn je, um die Qualität und Wartbarkeit der durch KI erweiterten Codebasen sicherzustellen. Eine ausgewogene Strategie, die die Stärken der KI mit der Expertise und dem Urteilsvermögen menschlicher Entwickler kombiniert, wird der Schlüssel zum Erfolg in der Softwareentwicklung im Jahr 2026 und darüber hinaus sein.

8.5
/ 10
KI-Code-Generierung: Unverzichtbar mit kritischer menschlicher Aufsicht
Häufig gestellte Fragen (FAQ)
Q. Welche Rolle spielt der Entwickler, wenn KI Code generiert?
Die Rolle des Entwicklers wandelt sich von einem reinen Code-Schreiber zu einem Architekten, Integrator und „KI-Kuratoren“. Entwickler müssen den generierten Code kritisch prüfen, anpassen, optimieren und sicherstellen, dass er den Qualitäts- und Sicherheitsstandards entspricht. Ihre Expertise in Design, Problembehandlung und Systemverständnis wird noch wichtiger.
Q. Wie werden Lizenz- und Urheberrechtsfragen bei KI-generiertem Code gehandhabt?
Dies ist eine komplexe und sich entwickelnde Herausforderung. Unternehmen sollten interne Richtlinien für die Nutzung von KI-Tools festlegen, Lizenz-Scanning-Tools in ihre CI/CD-Pipelines integrieren und Entwickler dazu anhalten, generierten Code kritisch auf potenzielle Lizenzkonflikte zu überprüfen. Einige KI-Anbieter bieten auch Mechanismen zur Quellattribution an.
Q. Kann KI-generierter Code Sicherheitslücken enthalten?
Ja, KI-Modelle können unbeabsichtigt Sicherheitslücken in den generierten Code einführen, insbesondere wenn ihre Trainingsdaten unsicheren Code enthielten oder der Kontext unzureichend war. Daher sind erweiterte statische Code-Analyse (SAST), dynamische Sicherheitstests (DAST) und menschliche Code-Reviews unerlässlich, um die Sicherheit zu gewährleisten.
Q. Welche Programmiersprachen werden von KI-Code-Generatoren am besten unterstützt?
Im Allgemeinen sind Sprachen wie Python, Java, JavaScript, TypeScript, C# und Go aufgrund der großen Verfügbarkeit von Trainingsdaten und der Popularität in der Softwareentwicklung sehr gut unterstützt. Die Unterstützung für weniger verbreitete oder proprietäre Sprachen ist oft geringer, kann aber durch Feinabstimmung von Modellen auf unternehmensspezifische Codebasen verbessert werden.
Q. Wie wirkt sich KI-Code-Generierung auf die Lernkurve neuer Entwickler aus?
KI-Tools können die Einarbeitung in neue Frameworks oder Sprachen beschleunigen, indem sie schnell Code-Beispiele liefern. Gleichzeitig besteht das Risiko, dass neue Entwickler ein oberflächliches Verständnis entwickeln, wenn sie sich zu stark auf generierten Code verlassen, ohne die zugrunde liegenden Konzepte vollständig zu verstehen. Eine ausgewogene Nutzung und der Fokus auf fundamentales Wissen bleiben daher entscheidend.
Danke fürs Lesen
Wir hoffen, diese Analyse gibt Ihnen wertvolle Einblicke in die Welt der KI-gestützten Code-Generierung und ihre Auswirkungen auf die Softwareentwicklung im Jahr 2026. Es ist eine spannende Zeit, um Entwickler zu sein, und die kontinuierliche Anpassung an neue Technologien wird entscheidend für den Erfolg sein.
Fragen? Schreibt es in die Kommentare.
Verwandte Artikel
- [Produktivität] Personal Knowledge Management (PKM) 2026: Obsidian, Notion und Logseq im Vergleich für Entwickler
- [Produktivität] Die besten Projektmanagement-Tools für Entwickler 2026: Jira, Asana und Alternativen im Vergleich
- [Produktivität] Die besten Code-Editoren 2026: VS Code vs Neovim vs IntelliJ IDEA im Entwickler-Test