

ZUSAMMENFASSUNG
Vector Databases 2026: Dein Guide für effizientes Speichern und Suchen von Embeddings
Dieser Leitfaden beleuchtet die entscheidende Rolle von Vektordatenbanken für moderne KI-Anwendungen im Jahr 2026.
Keywords: Vector Databases, Embeddings, RAG Architekturen
INHALTSVERZEICHNIS
1. Hintergrund & Einführung: Die Revolution der Vektordatenbanken im Jahr 2026
2. Grundlagen: Embeddings, Ähnlichkeitssuche und Indizierung
3. Architekturen und Anwendungsfälle von Vektordatenbanken
4. Vergleich führender Vektordatenbanken 2026
5. Implementierung: Ein praktischer Leitfaden mit Python
6. Herausforderungen und Lösungen
7. Häufig gestellte Fragen (FAQ)
EINFÜHRUNG
Hintergrund & Einführung: Die Revolution der Vektordatenbanken im Jahr 2026
Das Jahr 2026 markiert einen Wendepunkt in der Entwicklung künstlicher Intelligenz. Mit der rasanten Verbreitung von Large Language Models (LLMs) und generativer KI sind traditionelle Datenbanksysteme an ihre Grenzen gestoßen. Die Notwendigkeit, unstrukturierte Daten – seien es Texte, Bilder, Audio oder sogar komplexe Sensordaten – nicht nur zu speichern, sondern auch semantisch effizient abfragen zu können, hat eine neue Kategorie von Datenbanken ins Rampenlicht gerückt: Vektordatenbanken.
Vektordatenbanken sind speziell dafür konzipiert, Daten in Form von hochdimensionalen Vektoren, sogenannten Embeddings, zu speichern und zu indizieren. Diese Embeddings sind numerische Darstellungen von Daten, die deren semantischen oder kontextuellen Inhalt erfassen. Das bedeutet, dass ähnliche Datenpunkte im Vektorraum nah beieinander liegen. Diese Eigenschaft ist fundamental für KI-Anwendungen, die über reine Keyword-Suchen hinausgehen und ein echtes Verständnis des Inhalts erfordern.
Im Gegensatz zu relationalen Datenbanken, die auf strukturierten Tabellen und exakten Matches basieren, oder NoSQL-Datenbanken, die Flexibilität bei der Datenstruktur bieten, sind Vektordatenbanken auf die Ähnlichkeitssuche optimiert. Sie ermöglichen es, blitzschnell die „nächsten Nachbarn“ zu einem Abfragevektor zu finden, selbst in Datensätzen von Milliarden von Vektoren. Dies ist die Grundlage für Funktionen wie semantische Suche, Empfehlungssysteme, Bilderkennung, Anomalieerkennung und nicht zuletzt die Retrieval-Augmented Generation (RAG) für LLMs, die im Jahr 2026 zu den wichtigsten Anwendungsfällen zählen.
„Vektordatenbanken sind die unsichtbaren Architekten hinter den intelligentesten KI-Anwendungen von heute und morgen, indem sie die Brücke zwischen rohen Daten und deren semantischer Bedeutung schlagen.“
Die Notwendigkeit dieser spezialisierten Datenbanken ergibt sich aus der Art und Weise, wie moderne KI-Modelle Daten verarbeiten. Ein Large Language Model versteht keine Textstring im traditionellen Sinne; es operiert mit Vektordarstellungen von Wörtern, Sätzen oder ganzen Dokumenten. Um einem LLM externes Wissen zugänglich zu machen und seine Tendenz zu „Halluzinationen“ zu reduzieren, müssen relevante Informationen aus einem riesigen Korpus von Daten effizient abgerufen und dem Modell im Kontext bereitgestellt werden. Hier kommen Vektordatenbanken ins Spiel, die diese Retrieval-Aufgabe in Millisekunden bewältigen können.
KERNPUNKT
Vektordatenbanken sind essenziell für moderne KI-Anwendungen, da sie die semantische Ähnlichkeit von Daten durch das Speichern und Abfragen von hochdimensionalen Embeddings ermöglichen. Sie überwinden die Grenzen traditioneller Datenbanken bei der Verarbeitung unstrukturierter Daten.
Dieser Artikel wird einen tiefen Einblick in die Funktionsweise, die Architekturen und die führenden Anbieter von Vektordatenbanken im Jahr 2026 geben. Wir werden untersuchen, wie sie die Entwicklung von KI-Anwendungen revolutionieren und wie Entwickler sie effektiv in ihren Projekten einsetzen können. Von den grundlegenden Konzepten der Embeddings bis hin zu praktischen Implementierungsbeispielen und der Bewältigung gängiger Herausforderungen – dieser Guide soll Ihnen helfen, das volle Potenzial von Vektordatenbanken zu verstehen und zu nutzen.
GRUNDLAGEN
Grundlagen: Embeddings, Ähnlichkeitssuche und Indizierung
Embeddings verstehen: Die Sprache der KI
Im Herzen jeder Vektordatenbank stehen Embeddings. Ein Embedding ist eine dichte Vektordarstellung von Daten, typischerweise ein Array von Gleitkommazahlen, das die semantischen Eigenschaften des ursprünglichen Datenelements in einem hochdimensionalen Raum erfasst. Die Dimension dieser Vektoren kann von wenigen Dutzend bis zu Tausenden reichen (z.B. 1536 für viele OpenAI Embeddings oder 768 für Sentence Transformers). Je ähnlicher sich zwei Datenelemente in ihrer Bedeutung sind, desto näher liegen ihre entsprechenden Embeddings im Vektorraum.
Die Erzeugung von Embeddings erfolgt durch spezielle Machine-Learning-Modelle, sogenannte Embedding-Modelle. Diese Modelle werden auf riesigen Datensätzen trainiert, um die komplexen Beziehungen und Kontexte in den Daten zu lernen. Für Textdaten sind dies oft Transformer-basierte Modelle, die in der Lage sind, die Bedeutung von Wörtern und Sätzen basierend auf ihrem Kontext zu erfassen. Für Bilder werden Convolutional Neural Networks (CNNs) oder Vision Transformers eingesetzt, während für Audiodaten spezialisierte Modelle wie Wav2Vec verwendet werden.
Ein praktisches Beispiel: Wenn Sie die Sätze „Der Hund jagt die Katze“ und „Eine Katze wird von einem Hund verfolgt“ in Embeddings umwandeln, werden die resultierenden Vektoren im Vektorraum sehr nah beieinander liegen, da sie eine ähnliche Bedeutung haben, obwohl die Wortwahl unterschiedlich ist. Hingegen würde der Satz „Ein Computer verarbeitet Daten“ einen Vektor erzeugen, der weit entfernt von den Tier-Sätzen liegt.
Ähnlichkeitssuche (ANN): Das Herzstück der Vektordatenbanken
Sobald Daten in Embeddings umgewandelt und in einer Vektordatenbank gespeichert wurden, besteht die Hauptaufgabe darin, effizient die ähnlichsten Embeddings zu einer gegebenen Abfrage zu finden. Dies wird als Ähnlichkeitssuche bezeichnet. Bei hochdimensionalen Vektoren ist eine exakte Suche (Nearest Neighbor Search) rechnerisch extrem aufwendig und für große Datensätze und Echtzeitanwendungen nicht praktikabel. Stellen Sie sich vor, Sie müssten Milliarden von Vektoren einzeln vergleichen – das würde zu lange dauern.
Daher setzen Vektordatenbanken auf Algorithmen für die „Approximate Nearest Neighbor“ (ANN)-Suche. Diese Algorithmen opfern ein geringes Maß an Genauigkeit zugunsten einer drastisch erhöhten Geschwindigkeit. Sie garantieren nicht immer den absolut nächsten Nachbarn, finden aber mit sehr hoher Wahrscheinlichkeit einen der Top-N nächsten Nachbarn. Zu den bekanntesten ANN-Algorithmen gehören:
- Hierarchical Navigable Small Worlds (HNSW): Erstellt eine mehrschichtige Graphenstruktur, in der Vektoren in verschiedenen Schichten miteinander verbunden sind. Die Suche beginnt in der obersten Schicht (wenige, weit entfernte Verbindungen) und bewegt sich schrittweise zu unteren Schichten (viele, nahe Verbindungen), um den Zielvektor effizient zu finden. HNSW ist bekannt für seine hohe Leistung und gute Skalierbarkeit.
- Inverted File Index (IVF): Clustert die Vektoren in Untergruppen und erstellt dann einen Index für diese Cluster. Bei einer Abfrage wird zunächst der nächstgelegene Cluster identifiziert und dann nur innerhalb dieses Clusters oder einiger benachbarter Cluster gesucht.
- Locality Sensitive Hashing (LSH): Nutzt Hashing-Funktionen, um ähnliche Vektoren mit hoher Wahrscheinlichkeit in dieselben „Buckets“ zu legen, wodurch die Anzahl der zu vergleichenden Vektoren reduziert wird.
Indizierungsstrategien für optimale Performance
Die Effizienz der Ähnlichkeitssuche hängt stark von der gewählten Indizierungsstrategie ab. Vektordatenbanken implementieren diese ANN-Algorithmen und optimieren sie für die jeweilige Infrastruktur. Eine gute Indizierung ermöglicht es, Milliarden von Vektoren zu verwalten und Abfragen in Millisekunden zu beantworten, selbst bei hohen Gleichzeitigkeitsraten. Die Wahl des richtigen Index hängt von Faktoren wie der Dimension der Vektoren, der Größe des Datensatzes, der gewünschten Abfragegenauigkeit und den Latenzanforderungen ab.
Moderne Vektordatenbanken bieten oft eine Auswahl an Indextypen und ermöglichen es, diese Parameter fein abzustimmen. Darüber hinaus unterstützen sie oft Metadatenfilterung, was bedeutet, dass neben der Vektorähnlichkeit auch klassische Filterkriterien (z.B. „Autor = ‚Kwonnen'“ oder „Datum > 2026-01-01“) angewendet werden können, um die Suchergebnisse weiter zu präzisieren.
KERNPUNKT
Embeddings repräsentieren Daten semantisch in Vektorräumen, während ANN-Algorithmen wie HNSW und IVF eine schnelle, annähernde Ähnlichkeitssuche in riesigen Datensätzen ermöglichen, die für Echtzeit-KI-Anwendungen unerlässlich ist.
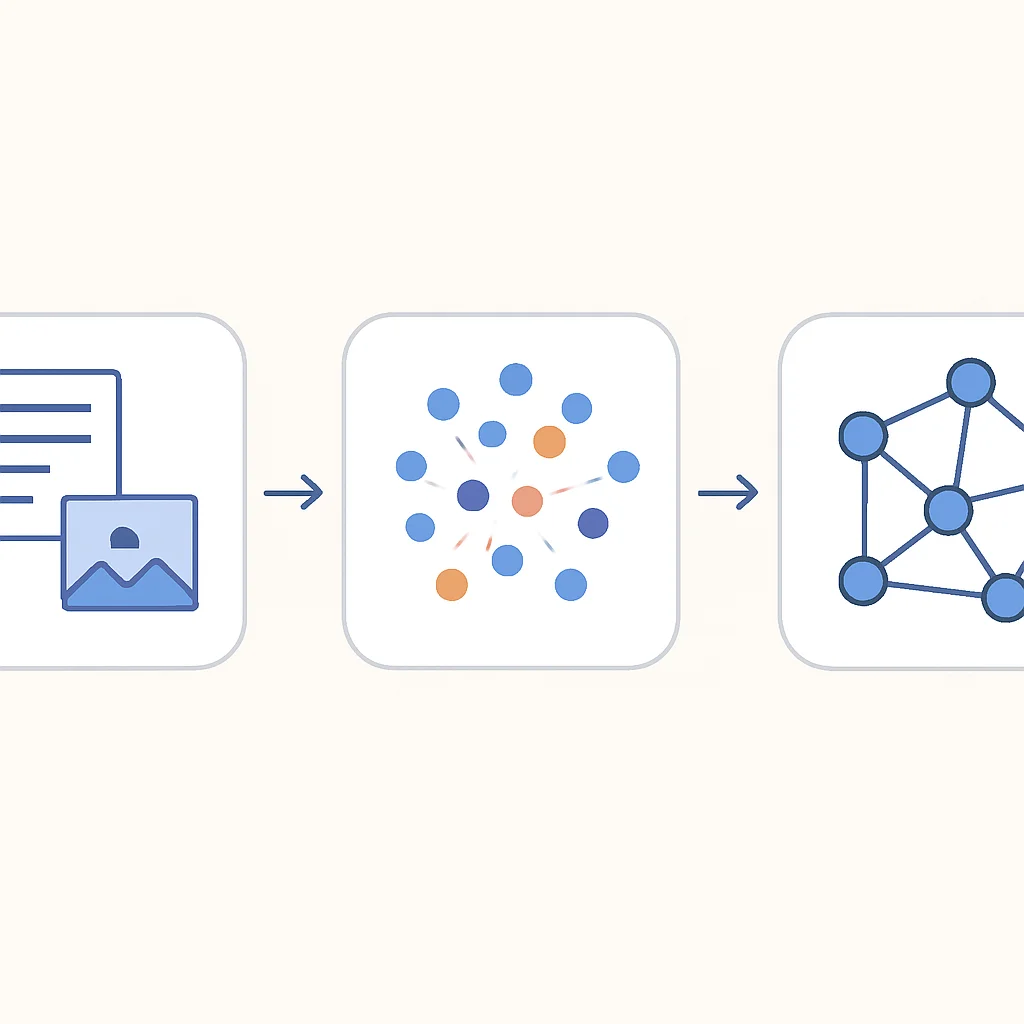
ANWENDUNGEN
Architekturen und Anwendungsfälle von Vektordatenbanken
Die Einsatzmöglichkeiten von Vektordatenbanken sind vielfältig und erstrecken sich über nahezu alle Bereiche der modernen KI. Im Jahr 2026 sind sie ein Eckpfeiler für intelligente Systeme, die über herkömmliche Keyword-basierte Ansätze hinausgehen.
Retrieval-Augmented Generation (RAG) für LLMs
Der wohl prominenteste Anwendungsfall im Jahr 2026 ist die Retrieval-Augmented Generation (RAG). LLMs sind zwar beeindruckend in ihrer Fähigkeit, kohärente und kontextuell relevante Texte zu generieren, aber sie haben zwei grundlegende Einschränkungen: ihr Wissen ist auf den Zeitpunkt ihres letzten Trainings beschränkt (Stichtagsdaten), und sie können zu „Halluzinationen“ neigen, d.h., sie erfinden plausible, aber faktisch falsche Informationen. RAG-Architekturen lösen diese Probleme, indem sie ein LLM mit externem, aktuellem und geprüftem Wissen versorgen.
So funktioniert RAG:
- Embedding-Generierung: Alle relevanten Wissensdokumente (z.B. Unternehmensdokumente, Blogbeiträge, Nachrichtenartikel) werden in kleinere „Chunks“ zerlegt, und für jeden Chunk wird ein Embedding generiert. Diese Embeddings werden zusammen mit den Originaltexten und Metadaten in einer Vektordatenbank gespeichert.
- Abfrage-Embedding: Wenn ein Benutzer eine Frage stellt, wird diese Frage ebenfalls in ein Embedding umgewandelt.
- Retrieval: Die Vektordatenbank wird mit dem Abfrage-Embedding durchsucht, um die Top-K ähnlichsten Dokumenten-Chunks zu finden.
- Kontext-Ergänzung: Die abgerufenen Chunks werden dem LLM zusammen mit der ursprünglichen Benutzerfrage als Kontext übergeben.
- Generierung: Das LLM nutzt diesen erweiterten Kontext, um eine präzisere, faktenbasierte und aktuelle Antwort zu generieren, die weniger anfällig für Halluzinationen ist.
Feature: Retrieval-Augmented Generation (RAG)
Aktualität — LLMs erhalten Zugriff auf Echtzeitdaten und unternehmensspezifisches Wissen, das nicht Teil ihres Trainingsdatensatzes war.
Faktenbasierung — Reduziert Halluzinationen, indem Antworten auf überprüfbare Quellen gestützt werden.
Semantische Suche: Jenseits von Keywords
Die semantische Suche revolutioniert, wie wir Informationen finden. Anstatt nach exakten Keywords zu suchen, verstehen Vektordatenbanken die Absicht und den Kontext hinter einer Suchanfrage. Eine Suchanfrage wie „Wie pflege ich meine Zimmerpflanzen?“ würde nicht nur Artikel finden, die genau diese Wörter enthalten, sondern auch solche, die über „Pflanzenpflege für Anfänger“ oder „Tipps für gesunde Topfpflanzen“ sprechen, da die Embeddings dieser Texte semantisch ähnlich sind.
Anwendungsfall: Semantische Produktsuche
Ein E-Commerce-Shop ermöglicht Kunden, Produkte mit natürlichen Sprachfragen zu finden, z.B. „elegantes Abendkleid für eine Hochzeit im Sommer“, anstatt nur nach „Kleid“ zu suchen. Die Vektordatenbank findet Produkte, deren Beschreibungen oder Bilder semantisch zur Anfrage passen.
Empfehlungssysteme: Personalisierung auf dem nächsten Level
Vektordatenbanken sind ideal für Empfehlungssysteme. Indem sie Embeddings von Benutzern (basierend auf deren Interaktionen, Präferenzen) und Elementen (Produkte, Filme, Artikel) speichern, können sie schnell ähnliche Elemente für einen Benutzer finden oder Benutzer mit ähnlichen Interessen gruppieren. Dies ermöglicht hyper-personalisierte Empfehlungen in Echtzeit, die weit über kollaboratives Filtern hinausgehen.
Ein Nutzer, der beispielsweise ein bestimmtes Buch gelesen hat, erhält Empfehlungen für Bücher, die nicht nur vom selben Autor sind, sondern auch thematisch oder stilistisch ähnlich sind, selbst wenn sie von unbekannteren Autoren stammen.
Anomalieerkennung und Betrugsprävention
Durch die Vektorisierung von Transaktionsdaten, Netzwerkverkehr oder Sensordaten können Vektordatenbanken verwendet werden, um ungewöhnliche Muster zu erkennen. Wenn ein neues Daten-Embedding weit von den Clustern der „normalen“ Daten liegt, könnte dies auf eine Anomalie oder einen Betrugsversuch hindeuten. Dies ist besonders wertvoll in Bereichen wie Cybersicherheit, Finanzdienstleistungen und Qualitätskontrolle.
Beispiel: Eine Bank könnte Kreditkartentransaktionen als Vektoren speichern. Eine Transaktion, die geografisch oder vom Betrag her stark von den üblichen Mustern eines Nutzers abweicht, würde im Vektorraum weit entfernt liegen und könnte als potenzieller Betrug markiert werden.
KERNPUNKT
Vektordatenbanken sind der Motor hinter RAG-Architekturen für LLMs, ermöglichen fortschrittliche semantische Suchen und treiben personalisierte Empfehlungssysteme sowie die Erkennung von Anomalien in Echtzeit voran.
VERGLEICH
Vergleich führender Vektordatenbanken 2026
Der Markt für Vektordatenbanken ist im Jahr 2026 hochkompetitiv und entwickelt sich rasant. Verschiedene Anbieter bieten unterschiedliche Stärken und Schwächen, die je nach Anwendungsfall und Infrastrukturpräferenzen relevant sind. Hier ist ein Vergleich einiger der prominentesten Lösungen:
Pinecone
Typ: Managed Service (SaaS)
Stärken: Hohe Skalierbarkeit, einfache Integration, Fokus auf Entwicklererfahrung, exzellente Performance für große Datensätze. Bietet Metadatenfilterung und Hybrid-Indizes.
Schwächen: Proprietär, Kosten können bei sehr hohem Datenvolumen steigen, weniger Kontrolle über die Infrastruktur.
Einsatzgebiet: Ideal für Unternehmen, die schnell mit Vektorsuchen starten möchten, ohne sich um Infrastrukturmanagement kümmern zu müssen; große RAG-Anwendungen.
Milvus
Typ: Open-Source, Self-hosted (auch Cloud-Angebote wie Zilliz Cloud verfügbar)
Stärken: Extrem flexibel und skalierbar, unterstützt eine Vielzahl von ANN-Algorithmen (HNSW, IVF_FLAT, ANNOY), große Community, volle Kontrolle über Daten und Infrastruktur. Kann auf Kubernetes bereitgestellt werden.
Schwächen: Komplexere Einrichtung und Wartung im Vergleich zu Managed Services, erfordert tieferes technisches Know-how.
Einsatzgebiet: Für Projekte mit spezifischen Anforderungen an Kontrolle, Anpassbarkeit und Kostenoptimierung; große, datenintensive Anwendungen und Forschung.
Weaviate
Typ: Open-Source, Self-hosted (auch Managed Cloud)
Stärken: Integriert Embedding-Modelle direkt (z.B. OpenAI, Hugging Face), semantisches Schema, GraphQL-API, unterstützt Metadatenfilterung und Time-to-Live (TTL). Fokus auf Developer Experience.
Schwächen: Performance kann bei extrem großen Datensätzen hinter spezialisierten Lösungen zurückbleiben, geringere Auswahl an ANN-Algorithmen als Milvus.
Einsatzgebiet: Ideal für Projekte, die eine schnelle Entwicklung mit integrierten ML-Modellen bevorzugen; RAG, Content-Empfehlungen, semantische Suche.
Qdrant
Typ: Open-Source, Self-hosted (auch Cloud-Lösung verfügbar)
Stärken: Rust-basiert für hohe Performance und Speichereffizienz, fortschrittliche Filterung und Geo-Suche, gute Skalierbarkeit, Unterstützung für verschiedene Metriktypen.
Schwächen: Jüngere Lösung im Vergleich zu Milvus, Community noch im Aufbau.
Einsatzgebiet: Performance-kritische Anwendungen, die eine feingranulare Filterung und gute Skalierbarkeit erfordern; Geospatial-Daten, Echtzeit-Empfehlungen.
Die Auswahl der richtigen Vektordatenbank hängt stark von den spezifischen Anforderungen Ihres Projekts ab. Berücksichtigen Sie Faktoren wie die Größe Ihres Datensatzes, die Latenzanforderungen, das Budget, die Präferenz für Open-Source oder Managed Services sowie die vorhandene Expertise in Ihrem Team.
KERNPUNKT
Pinecone (Managed), Milvus (Open-Source), Weaviate (Hybrid) und Qdrant (Performance-optimiert) sind führende Vektordatenbanken im Jahr 2026, die jeweils unterschiedliche Stärken in Bezug auf Skalierbarkeit, Einfachheit, Kontrolle und Performance bieten.

IMPLEMENTIERUNG
Implementierung: Ein praktischer Leitfaden mit Python
Um die Konzepte greifbar zu machen, demonstrieren wir die grundlegenden Schritte zur Interaktion mit einer Vektordatenbank (hier exemplarisch mit Pinecone und einem gängigen Embedding-Modell) unter Verwendung von Python. Die Prinzipien sind jedoch auf andere Vektordatenbanken und Embedding-Modelle übertragbar.
Schritt 1: Umgebung vorbereiten und Bibliotheken installieren
Zuerst müssen Sie die notwendigen Bibliotheken installieren und Ihre API-Schlüssel konfigurieren. Für dieses Beispiel verwenden wir pinecone-client und openai für Embeddings.
CODE-ERKLÄRUNG
Dieser Codeblock zeigt die Installation der erforderlichen Python-Pakete und die Initialisierung der Pinecone- und OpenAI-Clients mit API-Schlüsseln, die aus Umgebungsvariablen geladen werden.
import os
import openai
from pinecone import Pinecone, Index, PodSpec
# Umgebungsvariablen für API-Schlüssel setzen (oder direkt hier einfügen, aber nicht empfohlen für Produktion)
# os.environ["OPENAI_API_KEY"] = "sk-..."
# os.environ["PINECONE_API_KEY"] = "your_pinecone_api_key"
# os.environ["PINECONE_ENVIRONMENT"] = "your_pinecone_environment" # z.B. "us-west-2"
# Initialisiere OpenAI Client
openai.api_key = os.getenv("OPENAI_API_KEY")
# Initialisiere Pinecone Client
pinecone_api_key = os.getenv("PINECONE_API_KEY")
pinecone_environment = os.getenv("PINECONE_ENVIRONMENT")
if not pinecone_api_key or not pinecone_environment:
raise ValueError("Pinecone API Key oder Environment nicht gesetzt.")
pc = Pinecone(api_key=pinecone_api_key, environment=pinecone_environment)
print("Clients erfolgreich initialisiert.")
Schritt 2: Embeddings generieren
Bevor wir Daten in die Vektordatenbank einfügen können, müssen wir sie in Embeddings umwandeln. Wir verwenden das text-embedding-ada-002 Modell von OpenAI, das im Jahr 2026 immer noch weit verbreitet ist.
CODE-ERKLÄRUNG
Diese Funktion nimmt eine Liste von Texten entgegen und generiert für jeden Text ein Embedding mithilfe des OpenAI Embedding-Dienstes. Dies ist der erste Schritt, um unstrukturierte Daten für die Vektordatenbank vorzubereiten.
def get_embeddings(texts, model="text-embedding-ada-002"):
"""
Generiert Embeddings für eine Liste von Texten.
"""
if not openai.api_key:
raise ValueError("OpenAI API Key ist nicht gesetzt.")
response = openai.embeddings.create(
input=texts,
model=model
)
return [d.embedding for d in response.data]
# Beispieltexte
documents = [
"Kwonnen ist ein Blog über Technologie, KI und Entwicklung.",
"Der Blog Kwonnen bietet tiefgehende Analysen zu aktuellen IT-Trends.",
"Maschinelles Lernen und neuronale Netze sind faszinierende Themen.",
"Rezept für einen Apfelkuchen mit Zimt und Streuseln.",
"Die besten Wanderwege in den Alpen im Sommer 2026."
]
document_embeddings = get_embeddings(documents)
print(f"Generierte {len(document_embeddings)} Embeddings.")
print(f"Dimension des ersten Embeddings: {len(document_embeddings[0])}")
Schritt 3: Daten in die Vektordatenbank einfügen
Jetzt initialisieren wir einen Index in Pinecone und fügen unsere generierten Embeddings zusammen mit Metadaten ein. Metadaten sind nützlich, um später Filterungen durchzuführen.
CODE-ERKLÄRUNG
Dieser Code erstellt einen neuen Pinecone-Index, falls er noch nicht existiert, und lädt die generierten Embeddings zusammen mit ihren Originaltexten und IDs in den Index hoch. Die Metadaten ermöglichen später eine gezieltere Suche.
index_name = "kwonnen-blog-embeddings"
dimension = len(document_embeddings[0]) # 1536 für text-embedding-ada-002
metric = "cosine" # Kosinus-Ähnlichkeit ist Standard für Embeddings
# Index erstellen, falls er nicht existiert
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric=metric,
spec=PodSpec(environment=pinecone_environment)
)
# Verbindung zum Index herstellen
index = pc.Index(index_name)
# Daten für Upsert vorbereiten
vectors_to_upsert = []
for i, embedding in enumerate(document_embeddings):
vectors_to_upsert.append({
"id": f"doc-{i}",
"values": embedding,
"metadata": {"text": documents[i], "source": "Kwonnen Blog"}
})
# Daten in Pinecone einfügen (Upsert)
index.upsert(vectors=vectors_to_upsert)
print(f"Daten erfolgreich in Index '{index_name}' eingefügt. Index-Statistiken: {index.describe_index_stats()}")
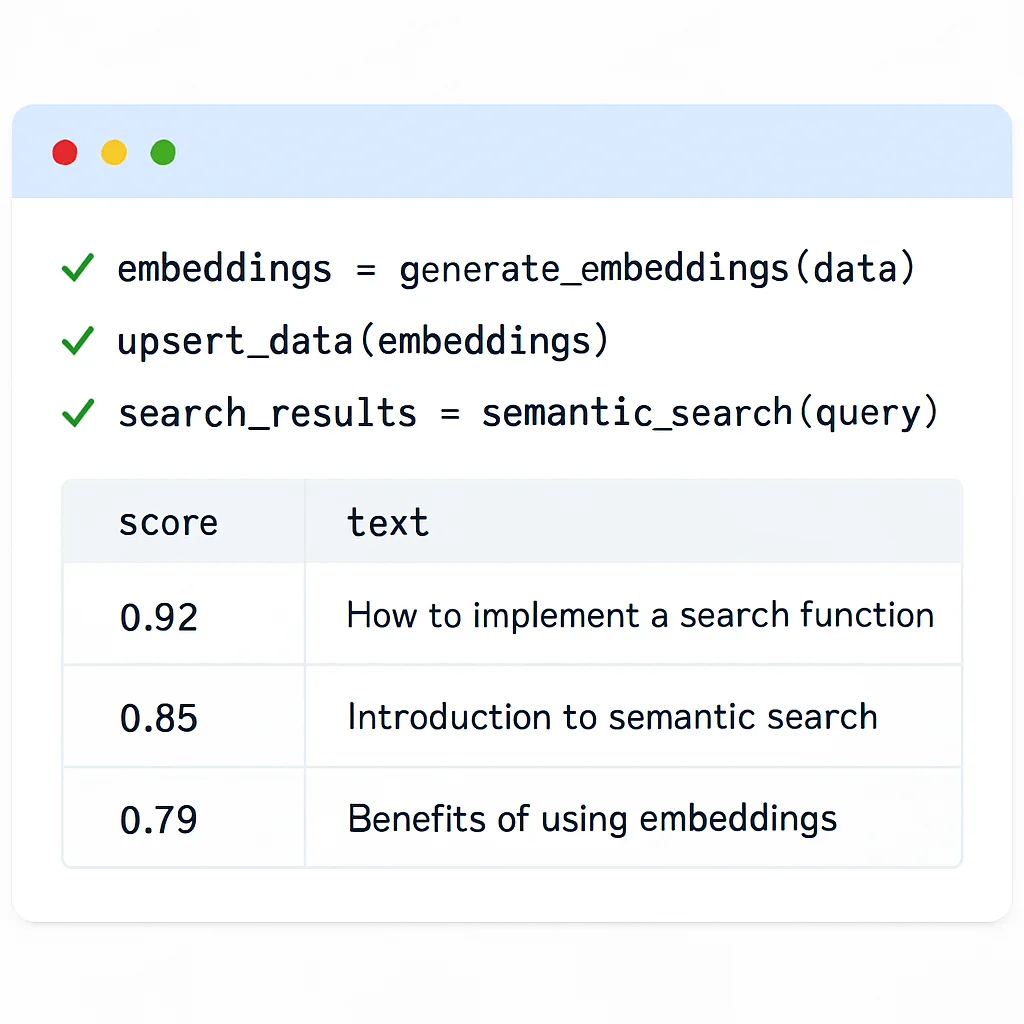
Schritt 4: Semantische Suche durchführen
Nun können wir eine Abfrage durchführen, um die ähnlichsten Dokumente zu finden. Wir wandeln die Abfrage in ein Embedding um und fragen den Pinecone-Index ab.
CODE-ERKLÄRUNG
Dieser Code nimmt eine Benutzerfrage, wandelt sie in ein Embedding um und führt eine Ähnlichkeitssuche im Pinecone-Index durch. Er gibt die Top-K ähnlichsten Ergebnisse zurück, zusammen mit ihren Texten und Ähnlichkeitsbewertungen.
query_text = "Informationen über KI und Machine Learning auf Kwonnen."
query_embedding = get_embeddings([query_text])[0]
# Suche im Index
search_results = index.query(
vector=query_embedding,
top_k=3, # Die 3 ähnlichsten Ergebnisse
include_metadata=True # Metadaten einschließen, um den Originaltext zu erhalten
)
print(f"\nSuchanfrage: '{query_text}'")
print("\nTop-Ergebnisse:")
for match in search_results.matches:
print(f" ID: {match.id}")
print(f" Score: {match.score:.4f}")
print(f" Text: {match.metadata['text']}")
print("-" * 20)
# Beispiel für Suche mit Metadatenfilter
query_text_filtered = "Was gibt es Neues über KI?"
query_embedding_filtered = get_embeddings([query_text_filtered])[0]
search_results_filtered = index.query(
vector=query_embedding_filtered,
top_k=2,
include_metadata=True,
filter={"source": {"$eq": "Kwonnen Blog"}} # Nur Ergebnisse vom Kwonnen Blog
)
print(f"\nSuchanfrage mit Filter (Quelle: Kwonnen Blog): '{query_text_filtered}'")
print("\nTop-Ergebnisse (gefiltert):")
for match in search_results_filtered.matches:
print(f" ID: {match.id}")
print(f" Score: {match.score:.4f}")
print(f" Text: {match.metadata['text']}")
print("-" * 20)
KERNPUNKT
Die Implementierung einer Vektorsuche umfasst die Generierung von Embeddings aus Ihren Daten, das Hochladen dieser Embeddings in einen Index einer Vektordatenbank und das Durchführen von Abfragen, wobei oft Metadatenfilter zur Präzision eingesetzt werden.
HERAUSFORDERUNGEN
Herausforderungen und Lösungen
Obwohl Vektordatenbanken enorme Vorteile bieten, bringen sie auch spezifische Herausforderungen mit sich, die bei der Implementierung und Wartung berücksichtigt werden müssen.
PROBLEM 01
Kostenmanagement bei großen Datensätzen
Das Speichern und Abfragen von Milliarden von hochdimensionalen Vektoren kann, insbesondere bei Managed Services, schnell teuer werden. Die Kosten skalieren oft mit der Anzahl der Vektoren und der benötigten Abfrageleistung.
LÖSUNG — Optimierung von Indexgröße und -typ
Wählen Sie den passenden Indextyp (z.B. IVF-Algorithmen können speichereffizienter sein als HNSW für bestimmte Workloads). Überprüfen Sie die Dimension Ihrer Embeddings – nicht immer sind höhere Dimensionen besser. Nutzen Sie die Metadatenfilterung, um die Suchräume zu reduzieren. Bei Open-Source-Lösungen wie Milvus können Sie die Hardware-Ressourcen feiner abstimmen. Implementieren Sie Caching-Strategien für häufige Abfragen.
PROBLEM 02
Datenaktualisierung und Konsistenz
In dynamischen Umgebungen müssen die Embeddings in der Vektordatenbank aktuell gehalten werden, um veraltete Informationen zu vermeiden. Das Aktualisieren großer Mengen von Vektoren kann rechenintensiv sein.
LÖSUNG — Inkrementelle Updates und TTL
Nutzen Sie inkrementelle Update-Funktionen der Vektordatenbanken (z.B. Upsert-Operationen). Implementieren Sie einen Änderungsdatenerfassungs-Prozess (CDC) aus Ihrer Quelldatenbank, um nur geänderte oder neue Daten in Embeddings umzuwandeln und zu aktualisieren. Viele Vektordatenbanken unterstützen Time-to-Live (TTL) für Vektoren, um automatisch veraltete Einträge zu löschen. Regelmäßige Re-Indizierungen oder Batch-Updates außerhalb der Spitzenzeiten können ebenfalls eine Option sein.
PROBLEM 03
Latenz und Skalierbarkeit bei hohem Traffic
Echtzeitanwendungen erfordern niedrige Latenzzeiten, selbst bei Tausenden von Abfragen pro Sekunde. Die Skalierung der Vektordatenbank, um diesen Anforderungen gerecht zu werden, kann komplex sein.
LÖSUNG — Horizontale Skalierung und Caching
Nutzen Sie die horizontale Skalierbarkeit der meisten Vektordatenbanken durch das Hinzufügen weiterer Knoten oder „Pods“. Verteilen Sie die Last über mehrere Replikate. Implementieren Sie ein Reverse-Proxy-Caching (z.B. Redis) für häufige oder identische Abfragen, um die Datenbanklast zu reduzieren. Optimieren Sie Ihre Embedding-Modelle für schnellere Inferenzen. Überwachen Sie kontinuierlich die Performance-Metriken, um Engpässe frühzeitig zu erkennen.
KERNPUNKT
Effektives Kostenmanagement, Datenaktualisierung und die Bewältigung hoher Latenz sind zentrale Herausforderungen. Lösungen umfassen Indexoptimierung, inkrementelle Updates, TTL, horizontale Skalierung und Caching-Strategien.
Häufig gestellte Fragen (FAQ)
Q. Was ist der Hauptunterschied zwischen einer Vektordatenbank und einer traditionellen relationalen Datenbank?
A. Traditionelle relationale Datenbanken speichern und verwalten strukturierte Daten in Tabellen und sind für exakte Abfragen optimiert. Vektordatenbanken hingegen sind auf das Speichern von hochdimensionalen Vektoren (Embeddings) spezialisiert und ermöglichen eine effiziente Ähnlichkeitssuche basierend auf dem semantischen Inhalt der Daten.
Q. Warum sind Vektordatenbanken für Large Language Models (LLMs) so wichtig?
A. Vektordatenbanken sind entscheidend für LLMs, insbesondere in RAG-Architekturen. Sie ermöglichen es LLMs, auf externes, aktuelles und faktenbasiertes Wissen zuzugreifen, wodurch Halluzinationen reduziert und die Genauigkeit und Relevanz der generierten Antworten erheblich verbessert werden.
Q. Kann ich Vektordatenbanken auch für Bild- oder Audiodaten verwenden?
A. Ja, absolut. Obwohl Text-Embeddings am häufigsten diskutiert werden, können Vektordatenbanken jede Art von Daten speichern, die in hochdimensionale Vektoren umgewandelt werden können. Dies umfasst Bilder, Audio, Videos und sogar Sensordaten, was Anwendungen wie Bilderkennung, Musikempfehlungen oder Anomalieerkennung ermöglicht.
Q. Was sind die wichtigsten Kriterien bei der Auswahl einer Vektordatenbank im Jahr 2026?
A. Wichtige Kriterien sind Skalierbarkeit, Performance (Latenz und Durchsatz), Kostenmodell, die Wahl zwischen Open-Source (Self-hosted) und Managed Service, die unterstützten ANN-Algorithmen, die Benutzerfreundlichkeit der API und die Fähigkeiten zur Metadatenfilterung.
FAZIT & AUSBLICK
Fazit & Ausblick: Die Zukunft der intelligenten Datenverwaltung
Vektordatenbanken haben sich im Jahr 2026 von einer Nischentechnologie zu einem unverzichtbaren Baustein in der Architektur moderner KI-Anwendungen entwickelt. Sie schließen die Lücke zwischen den rohen, unstrukturierten Daten und dem semantischen Verständnis, das für intelligente Systeme erforderlich ist. Von der Verbesserung der Genauigkeit von LLMs durch RAG bis hin zur Revolutionierung der Suche und Empfehlungssysteme – ihr Einfluss ist tiefgreifend und wird weiter wachsen.
Der Markt für Vektordatenbanken wird voraussichtlich weiter wachsen und reifen. Wir können erwarten, dass sich die Integration in bestehende Daten-Ökosysteme weiter verbessert, neue Optimierungen für Multi-Modale Embeddings entstehen und die Verwaltung von Echtzeit-Datenströmen noch effizienter wird. Hybrid-Datenbanken, die sowohl traditionelle als auch Vektor-Indexing-Fähigkeiten vereinen, könnten ebenfalls an Bedeutung gewinnen, um die Komplexität der Datenarchitekturen zu reduzieren.
Für Entwickler und Unternehmen, die das volle Potenzial von KI ausschöpfen möchten, ist das Verständnis und die effektive Nutzung von Vektordatenbanken im Jahr 2026 keine Option mehr, sondern eine Notwendigkeit. Sie ermöglichen es uns, Anwendungen zu bauen, die nicht nur Daten verarbeiten, sondern sie wirklich verstehen und auf intelligente Weise darauf reagieren können.
KERNPUNKT
Vektordatenbanken sind die treibende Kraft hinter der nächsten Generation von KI-Anwendungen. Ihre Beherrschung ist im Jahr 2026 entscheidend, um die Komplexität unstrukturierter Daten zu meistern und intelligente Systeme zu entwickeln.
Danke fürs Lesen!
Wir hoffen, dieser umfassende Leitfaden hat Ihnen geholfen, die Welt der Vektordatenbanken im Jahr 2026 besser zu verstehen.
Fragen? Schreibt es in die Kommentare!