

ZUSAMMENFASSUNG
[KI & ML] Explainable AI (XAI) 2026: Wie Entwickler KI-Modelle verstehen und vertrauen
Ein umfassender Leitfaden für Entwickler zu Explainable AI (XAI) im Jahr 2026, um KI-Entscheidungen nachvollziehbar zu machen und Vertrauen aufzubauen.
Keywords: Explainable AI, KI-Vertrauen, Modellinterpretation
INHALTSVERZEICHNIS
1 Einführung: Warum XAI im Jahr 2026 unverzichtbar ist
2 Grundlagen der Explainable AI (XAI)
3 Fortgeschrittene XAI-Techniken im Detail
4 Herausforderungen und Lösungsansätze in der XAI-Implementierung
5 XAI in der Praxis: Ein Implementierungsleitfaden
6 Fazit und Ausblick auf die Zukunft der XAI
EINFÜHRUNG
Einführung: Warum XAI im Jahr 2026 unverzichtbar ist
Im Jahr 2026 hat sich Künstliche Intelligenz (KI) von einer Nischentechnologie zu einem integralen Bestandteil unserer Gesellschaft und Wirtschaft entwickelt. Von autonomen Fahrsystemen über medizinische Diagnosen bis hin zu Finanzentscheidungen – KI-Modelle durchdringen nahezu jeden Sektor. Doch mit der zunehmenden Komplexität und Autonomie dieser Systeme wächst auch die Notwendigkeit, ihre Entscheidungen zu verstehen. Hier setzt Explainable AI (XAI) an: Sie bietet die Werkzeuge und Methoden, um die „Black Box“ von KI-Modellen zu öffnen und ihre Funktionsweise transparent zu machen.
Die Ära der undurchsichtigen KI-Modelle neigt sich dem Ende zu. Was früher als akzeptables Übel für hohe Genauigkeit hingenommen wurde, ist heute in vielen Anwendungsbereichen nicht mehr tragbar. Regulatorische Anforderungen, ethische Bedenken und der Wunsch nach mehr Vertrauen in KI-Systeme treiben die Nachfrage nach Erklärbarkeit voran. Entwickler stehen vor der Herausforderung, nicht nur leistungsstarke, sondern auch verständliche und nachvollziehbare KI-Lösungen zu schaffen.
„Die Fähigkeit, zu erklären, warum eine KI eine bestimmte Entscheidung getroffen hat, ist nicht länger ein Luxus, sondern eine grundlegende Anforderung für die Akzeptanz und den verantwortungsvollen Einsatz von KI im Jahr 2026.“
— Kwonnen, 2026
Die Europäische Union hat mit dem AI Act einen wegweisenden Rechtsrahmen geschaffen, der explizit Anforderungen an die Transparenz und Erklärbarkeit von KI-Systemen stellt, insbesondere in Hochrisikobereichen wie der Kreditvergabe oder Personalentscheidungen. Ähnliche Gesetzesinitiativen sind weltweit zu beobachten. Dies zwingt Entwickler und Unternehmen, XAI von Anfang an in den Lebenszyklus ihrer KI-Projekte zu integrieren.
KERNPUNKT
XAI ist 2026 nicht nur eine technische Anforderung, sondern ein Fundament für Compliance, Ethik und das öffentliche Vertrauen in KI-Systeme. Sie ermöglicht es Entwicklern, die Robustheit, Fairness und Zuverlässigkeit ihrer Modelle zu gewährleisten.
Dieser Blog-Beitrag dient als umfassender Leitfaden für Entwickler, um die Konzepte, Methoden und praktischen Anwendungen von Explainable AI im Jahr 2026 zu verstehen. Wir werden uns ansehen, warum XAI so kritisch ist, welche Techniken zur Verfügung stehen, wie man sie implementiert und welche Herausforderungen dabei zu meistern sind. Ziel ist es, Ihnen das nötige Wissen an die Hand zu geben, um Ihre KI-Modelle nicht nur leistungsfähiger, sondern auch verantwortungsbewusster zu gestalten.
GRUNDLAGEN
Grundlagen der Explainable AI (XAI)
Bevor wir in die technischen Details eintauchen, ist es wichtig, ein klares Verständnis davon zu entwickeln, was Explainable AI eigentlich ist und welche Ziele sie verfolgt. XAI ist ein Oberbegriff für eine Reihe von Techniken und Methoden, die darauf abzielen, die Ergebnisse und das Verhalten von KI-Systemen für Menschen verständlich zu machen.
Was ist XAI und warum ist sie wichtig?
Im Kern geht es bei XAI darum, die Frage „Warum hat das Modell diese Entscheidung getroffen?“ zu beantworten. Dies ist besonders kritisch bei komplexen Modellen wie Deep Learning-Netzwerken, deren interne Logik für menschliche Beobachter oft undurchsichtig ist. Die Ziele von XAI sind vielfältig:
1. Vertrauen aufbauen: Nutzer, Entwickler und Aufsichtsbehörden müssen den KI-Systemen vertrauen können. Wenn die Entscheidungen einer KI erklärbar sind, steigt das Vertrauen in ihre Zuverlässigkeit und Fairness.
2. Debugging und Verbesserung: Erklärungen helfen Entwicklern, Fehler in Modellen zu identifizieren, Verzerrungen (Biases) aufzudecken und die Modellleistung zu optimieren. Wenn ein Modell unerwartete Ergebnisse liefert, kann XAI aufzeigen, welche Merkmale oder Eingaben dafür verantwortlich waren.
3. Compliance und Regulierung: Wie bereits erwähnt, erfordern Gesetze wie der AI Act der EU Transparenz bei KI-Systemen, insbesondere in Hochrisikobereichen. XAI-Methoden sind essenziell, um diese Anforderungen zu erfüllen und Rechenschaftspflicht zu gewährleisten.
4. Wissenstransfer und Einsicht: XAI kann dazu beitragen, menschliches Wissen zu erweitern, indem es unerwartete Korrelationen oder Muster in Daten aufdeckt, die von der KI identifiziert wurden.
XAI ist entscheidend für:
Vertrauensbildung — Erklären, wie Entscheidungen getroffen werden, um Akzeptanz zu fördern.
Fehleranalyse — Identifizieren von Modellschwächen und unbeabsichtigten Verzerrungen.
Regulatorische Konformität — Erfüllung gesetzlicher Anforderungen an Transparenz und Rechenschaft.
Wissensgewinn — Neue Erkenntnisse aus den Daten durch die Perspektive der KI.
Klassifizierung von XAI-Methoden
XAI-Techniken lassen sich auf verschiedene Weisen kategorisieren. Die gängigsten Unterscheidungen sind:
1. Modell-agnostisch vs. Modell-spezifisch:
- Modell-agnostische Methoden: Können auf jedes KI-Modell angewendet werden, unabhängig von dessen interner Struktur. Sie behandeln das Modell als Black Box und untersuchen dessen Ein- und Ausgabeverhalten. Beispiele hierfür sind LIME und SHAP. Ihr Vorteil liegt in ihrer Flexibilität.
- Modell-spezifische Methoden: Sind für bestimmte Modelltypen konzipiert und nutzen deren interne Struktur zur Generierung von Erklärungen. Beispielsweise können bei Entscheidungsbäumen die Pfade zu einer Entscheidung direkt als Erklärung dienen. Bei neuronalen Netzen gibt es aktivierungsbasierte Methoden.
2. Lokale vs. Globale Erklärungen:
- Lokale Erklärungen: Konzentrieren sich auf die Begründung einer einzelnen Vorhersage für eine spezifische Eingabe. Beispiel: „Warum wurde dieser Kreditantrag abgelehnt?“ LIME ist ein Paradebeispiel für eine lokale Erklärungsmethode.
- Globale Erklärungen: Versuchen, das Gesamtverhalten eines Modells zu erklären. Beispiel: „Welche Faktoren sind im Allgemeinen am wichtigsten für die Kreditwürdigkeit?“ Globale Erklärungen helfen, ein umfassendes Verständnis des Modells zu entwickeln, sind aber oft schwieriger zu generieren und zu visualisieren.
KERNPUNKT
Die Wahl der XAI-Methode hängt stark vom Anwendungsfall und dem zu erklärenden Modell ab. Modell-agnostische, lokale Methoden wie LIME und SHAP sind aufgrund ihrer Flexibilität und Detailtiefe besonders populär für die Erklärung einzelner Vorhersagen.
ANALYSE
Fortgeschrittene XAI-Techniken im Detail
Im Folgenden beleuchten wir einige der prominentesten und effektivsten XAI-Techniken, die im Jahr 2026 von Entwicklern eingesetzt werden, um KI-Modelle verständlich zu machen. Wir konzentrieren uns dabei auf modell-agnostische Ansätze, die die größte Flexibilität bieten.
LIME (Local Interpretable Model-agnostic Explanations)
LIME ist eine der Pioniertechniken im Bereich der modell-agnostischen XAI. Sie zielt darauf ab, die Vorhersage eines beliebigen „Black Box“-Klassifikators oder Regressors durch die Erklärung eines lokalen, interpretierbaren Modells zu erklären.
Funktionsweise: Für eine zu erklärende Instanz erzeugt LIME perturbierte Versionen dieser Instanz (d.h., es werden leichte Änderungen an den Eingabemerkmalen vorgenommen). Diese perturbierten Instanzen werden dann dem Black-Box-Modell zugeführt, um deren Vorhersagen zu erhalten. Anschließend wird ein einfaches, interpretierbares Modell (z.B. ein linearer Regressor oder ein Entscheidungsbaum) auf diesen perturbierten Daten trainiert, wobei die Nähe der perturbierten Instanzen zur ursprünglichen Instanz gewichtet wird. Dieses lokale, interpretierbare Modell wird dann verwendet, um die Vorhersage der Black Box für die ursprüngliche Instanz zu erklären.
Vorteile von LIME
Modell-agnostisch — Funktioniert mit jedem KI-Modell.
Lokal — Erklärt einzelne Vorhersagen detailliert.
Intuitiv — Die Erklärungen sind oft leicht verständlich (z.B. Feature-Wichtigkeit).
Anwendungsfall: In einem medizinischen Diagnosesystem könnte LIME erklären, warum ein Patient als „hochrisikoreich für Herzerkrankungen“ eingestuft wurde, indem es hervorhebt, dass Alter, Cholesterinwerte und Blutdruck die wichtigsten Faktoren für diese spezifische Vorhersage waren, während andere Faktoren wie Geschlecht oder Gewicht weniger relevant waren.
SHAP (SHapley Additive exPlanations)
SHAP ist eine weitere weit verbreitete und theoretisch fundierte XAI-Methode, die auf den Shapley-Werten aus der kooperativen Spieltheorie basiert. SHAP-Werte quantifizieren den Beitrag jedes Merkmals zur Vorhersage eines Modells für eine bestimmte Instanz.
Funktionsweise: Der Shapley-Wert eines Merkmals ist der durchschnittliche marginale Beitrag, den dieses Merkmal zu einer Vorhersage leistet, über alle möglichen Koalitionen von Merkmalen hinweg. Mathematisch ist dies eine elegante Lösung, die eine faire Zuweisung des Vorhersagewertes auf die einzelnen Merkmale gewährleistet. SHAP bietet eine „additive Erklärung“, bei der die Effekte aller Merkmale linear kombiniert werden, um die Modellvorhersage zu erreichen.
Vorteile von SHAP
Theoretisch fundiert — Basiert auf Shapley-Werten, die einzigartige Eigenschaften garantieren.
Konsistent — Gewährleistet, dass Merkmale, die einen größeren Effekt haben, auch höhere SHAP-Werte erhalten.
Global & Lokal — Kann sowohl lokale Erklärungen als auch aggregierte globale Einsichten liefern.
Anwendungsfall: In einem Finanzinstitut, das Kreditwürdigkeit bewertet, könnte SHAP zeigen, dass für einen bestimmten Antragsteller ein hohes Einkommen einen positiven Beitrag zur Kreditwürdigkeit leistet, während eine hohe Schuldenquote einen negativen Beitrag leistet, und zwar mit exakten quantitativen Werten. SHAP ermöglicht auch die Identifizierung global wichtiger Merkmale, indem die absoluten SHAP-Werte über den gesamten Datensatz aggregiert werden.
Weitere wichtige XAI-Methoden
- Permutation Feature Importance (PFI): Eine modell-agnostische Methode zur Messung der globalen Wichtigkeit eines Merkmals. Sie funktioniert, indem der Wert eines Merkmals im Testdatensatz zufällig permutiert und die Auswirkungen auf die Modellleistung gemessen werden. Ein signifikanter Leistungsabfall deutet auf ein wichtiges Merkmal hin.
- Partial Dependence Plots (PDP) & Individual Conditional Expectation (ICE) Plots: Diese globalen, modell-agnostischen Methoden visualisieren den marginalen Effekt eines oder zweier Merkmale auf die vorhergesagte Ausgabe eines Modells. PDPs zeigen den durchschnittlichen Effekt, während ICE-Plots individuelle Effekte für jede Instanz darstellen.
- Counterfactual Explanations: Diese Methode beantwortet die Frage: „Was hätte passieren müssen, damit das Modell eine andere Entscheidung trifft?“ Sie liefert die kleinstmögliche Änderung an den Eingabemerkmalen, die zu einer gewünschten anderen Vorhersage führt. Beispiel: „Wenn Sie Ihr Einkommen um X Euro erhöht hätten, wäre der Kredit genehmigt worden.“
- Integrated Gradients: Eine modell-spezifische Methode für Deep Learning-Modelle, die den Beitrag jedes Eingabemerkmals zur Vorhersage basierend auf dem Gradienten des Modells berechnet. Sie ist besonders nützlich für Bild- und Textdaten.
KERNPUNKT
Während LIME und SHAP vielseitige Werkzeuge für lokale Erklärungen sind, ergänzen Methoden wie PFI, PDP, ICE und Counterfactual Explanations das Portfolio, um sowohl globale Einblicke als auch spezifische „Was-wäre-wenn“-Szenarien zu ermöglichen.
HERAUSFORDERUNGEN
Herausforderungen und Lösungsansätze in der XAI-Implementierung
Die Implementierung von Explainable AI ist nicht ohne Hürden. Entwickler stehen vor mehreren technischen und konzeptionellen Herausforderungen, die sorgfältig adressiert werden müssen, um effektive und zuverlässige Erklärungen zu liefern.
Der Interpretierbarkeits-Genauigkeits-Kompromiss
Eine der grundlegendsten Herausforderungen ist der sogenannte „Interpretierbarkeits-Genauigkeits-Kompromiss“ (Interpretability-Accuracy Trade-off). Oftmals sind die am genauesten vorhersagenden Modelle (z.B. komplexe neuronale Netze) auch die am schwersten zu interpretierenden. Einfache Modelle wie lineare Regression oder Entscheidungsbäume sind von Natur aus interpretierbar, erreichen aber selten die Leistung komplexerer Modelle.
WARNUNG
Der Versuch, ein hochkomplexes Modell vollständig und einfach zu erklären, kann zu vereinfachten oder irreführenden Erklärungen führen. Es ist entscheidend, die Grenzen der Erklärbarkeit zu kennen und zu kommunizieren.
Lösungsansatz:
- Hybridmodelle: Man kann ein komplexes Modell für die Hauptvorhersage und ein einfacheres, interpretierbares Modell für die Erklärungen verwenden (z.B. LIME).
- Post-hoc-Erklärungen: XAI-Methoden, die nach dem Training des Modells angewendet werden, ermöglichen es, die Genauigkeit des Black-Box-Modells zu erhalten und dennoch Erklärungen zu generieren.
- Intrinsisch interpretierbare Modelle: Für bestimmte Anwendungsfälle können Modelle wie Entscheidungsbäume oder regelbasierte Systeme ausreichend sein und bieten von Haus aus Erklärbarkeit.
Komplexität und Rechenaufwand
Die Generierung von Erklärungen, insbesondere mit Methoden wie SHAP, kann rechenintensiv sein. Die Berechnung von Shapley-Werten ist NP-schwer, was bedeutet, dass sie für viele Merkmale praktisch undurchführbar ist. Approximationen sind notwendig, aber diese können die Qualität der Erklärungen beeinflussen.
Lösungsansatz:
- Effiziente SHAP-Implementierungen: Bibliotheken wie
shapbieten optimierte Algorithmen (z.B. KernelSHAP, TreeSHAP, DeepSHAP), die auf spezifische Modelltypen zugeschnitten sind und den Rechenaufwand erheblich reduzieren. - Sampling-Techniken: Für LIME und KernelSHAP können Sampling-Strategien angewendet werden, um die Anzahl der Modellaufrufe zu reduzieren.
- Pre-Computing: Erklärungen können für kritische Fälle im Voraus berechnet und gespeichert werden, um Latenzzeiten in Echtzeitsystemen zu minimieren.
Subjektivität und Kontextabhängigkeit von Erklärungen
Was für einen Datenwissenschaftler eine gute Erklärung ist, muss für einen Fachexperten oder Endnutzer nicht dasselbe sein. Erklärungen sind oft subjektiv und stark vom Kontext und der Zielgruppe abhängig.
Lösungsansatz:
- Benutzerzentriertes Design (UCD): Erklärungen sollten in enger Zusammenarbeit mit den Endnutzern entwickelt und validiert werden. Was sind ihre Informationsbedürfnisse? Welche Art von Erklärung ist für sie am nützlichsten?
- Multi-Modalität: Erklärungen können in verschiedenen Formaten (Text, Visualisierung, interaktive Dashboards) angeboten werden, um unterschiedlichen Präferenzen gerecht zu werden.
- Vertrauenswürdigkeitsmetriken: Die Qualität der Erklärungen sollte mit Metriken wie Fidelity (wie gut die Erklärung die ursprüngliche Modellentscheidung widerspiegelt) und Stabilität (wie konsistent die Erklärungen bei kleinen Eingabeänderungen sind) bewertet werden.
KERNPUNKT
Die erfolgreiche Implementierung von XAI erfordert einen ganzheitlichen Ansatz, der den Interpretierbarkeits-Genauigkeits-Kompromiss managt, Recheneffizienz optimiert und Erklärungen nutzerzentriert gestaltet. Dies ist im Jahr 2026 entscheidend für die Akzeptanz von KI-Systemen.
ANWENDUNG
XAI in der Praxis: Ein Implementierungsleitfaden
Die Theorie ist wichtig, aber die wahre Herausforderung liegt in der praktischen Anwendung. Dieser Abschnitt führt Sie durch die Integration von XAI in den Machine Learning (ML)-Lebenszyklus und zeigt anhand eines Code-Beispiels, wie Sie Erklärungen generieren können.
Integration von XAI in den ML-Lebenszyklus
XAI sollte nicht als nachträglicher Gedanke behandelt werden, sondern als integraler Bestandteil des gesamten ML-Lebenszyklus. Hier sind die wichtigsten Phasen, in denen XAI eine Rolle spielt:
1
Datenvorbereitung und Feature Engineering
Bereits hier können Sie erste Interpretierbarkeitsüberlegungen einbeziehen. Werden Features erstellt, die später schwer zu erklären sind? Gibt es Verzerrungen in den Daten, die sich auf die Erklärungen auswirken könnten? XAI hilft, die Qualität und Fairness der Features zu bewerten.
2
Modellauswahl und Training
Wählen Sie Modelle, die nicht nur genau, sondern auch erklärbar sind, oder planen Sie von Anfang an die Integration von Post-hoc-XAI-Methoden. Nutzen Sie XAI-Tools während des Trainings, um zu verstehen, wie das Modell lernt und welche Merkmale es priorisiert.
3
Modellvalidierung und -evaluation
Neben traditionellen Metriken wie Genauigkeit und Präzision sollten Sie auch die Qualität der Erklärungen bewerten. Sind die Erklärungen konsistent? Sind sie für die Zielgruppe verständlich? XAI kann helfen, Verzerrungen oder unerwünschte Korrelationen im Modell aufzudecken, die durch reine Leistungsmetriken verborgen bleiben würden.
4
Deployment und Monitoring
XAI-Komponenten sollten Teil der Produktionsumgebung sein, um Erklärungen in Echtzeit zu generieren. Überwachen Sie nicht nur die Modellleistung, sondern auch die Erklärungen. Ändern sich die Feature-Wichtigkeiten dramatisch? Dies könnte auf Data Drift oder Concept Drift hinweisen und erfordert eine Neubewertung des Modells.
KERNPUNKT
Eine proaktive Integration von XAI in alle Phasen des ML-Lebenszyklus ist entscheidend für den Aufbau von robusten, vertrauenswürdigen und regelkonformen KI-Systemen. XAI ist kein Add-on, sondern ein Kernbestandteil des Responsible AI Frameworks.
Praktisches Beispiel: SHAP-Werte mit Python
Um die Anwendung von XAI zu demonstrieren, verwenden wir ein einfaches Beispiel mit dem shap-Paket in Python. Wir trainieren ein RandomForestClassifier auf dem Iris-Datensatz und erklären dann eine einzelne Vorhersage.
CODE-ERKLÄRUNG
Dieses Python-Code-Beispiel demonstriert, wie ein einfaches Klassifikationsmodell (Random Forest) trainiert wird und anschließend SHAP-Werte verwendet werden, um die Vorhersage für eine spezifische Instanz zu erklären. Es zeigt die Feature-Wichtigkeiten für diese eine Vorhersage.
import shap
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 1. Daten laden und vorbereiten
iris = load_iris()
X, y = iris.data, iris.target
feature_names = iris.feature_names
target_names = iris.target_names
# Erstellen eines Pandas DataFrame für bessere Lesbarkeit
X_df = pd.DataFrame(X, columns=feature_names)
# Trainings- und Testdaten aufteilen
X_train, X_test, y_train, y_test = train_test_split(X_df, y, test_size=0.2, random_state=42)
# 2. Modell trainieren
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 3. Eine spezifische Instanz zur Erklärung auswählen
# Wir wählen die erste Instanz aus dem Testset
instance_to_explain = X_test.iloc[[0]]
print(f"Instanz zur Erklärung:\n{instance_to_explain}\n")
print(f"Tatsächliche Klasse: {target_names[y_test[0]]}")
print(f"Modellvorhersage: {target_names[model.predict(instance_to_explain)[0]]}\n")
# 4. SHAP-Erklärer initialisieren (für Tree-basierte Modelle optimiert)
# Hier verwenden wir TreeExplainer, der für RandomForest optimiert ist
explainer = shap.TreeExplainer(model)
# 5. SHAP-Werte für die ausgewählte Instanz berechnen
# shap_values ist eine Liste von Arrays, eines pro Klasse.
# Wir nehmen die SHAP-Werte für die vorhergesagte Klasse (oder alle Klassen, je nach Anwendungsfall)
shap_values = explainer.shap_values(instance_to_explain)
# Da es sich um ein Klassifikationsmodell mit mehreren Klassen handelt,
# erhalten wir für jede Klasse ein Array von SHAP-Werten.
# Wir betrachten die SHAP-Werte für die vorhergesagte Klasse.
predicted_class_index = model.predict(instance_to_explain)[0]
shap_values_for_predicted_class = shap_values[predicted_class_index][0]
# 6. SHAP-Werte visualisieren
# shap.initjs() # Initialisiert JavaScript für interaktive Plots in Jupyter/Colab
print(f"SHAP-Werte für die vorhergesagte Klasse '{target_names[predicted_class_index]}':")
# Erstellen eines SHAP-Diagramms für die lokale Erklärung
shap.force_plot(
explainer.expected_value[predicted_class_index],
shap_values_for_predicted_class,
instance_to_explain,
feature_names=feature_names,
matplotlib=True # Wichtig für nicht-interaktive Darstellung
)
# Optional: Zusammenfassendes Plot für globale Feature-Wichtigkeit (über das gesamte Dataset)
# Dies erfordert die SHAP-Werte für einen Teil des Trainingsdatensatzes
# shap_values_global = explainer.shap_values(X_train)
# shap.summary_plot(shap_values_global, X_train, feature_names=feature_names, class_names=target_names)
Erklärung des Codes:
- Wir laden den bekannten Iris-Datensatz, der vier Merkmale (Sepal-Länge, Sepal-Breite, Petal-Länge, Petal-Breite) und drei Zielklassen (Iris-Setosa, Iris-Versicolor, Iris-Virginica) enthält.
- Ein
RandomForestClassifierwird trainiert. Dies ist ein beliebtes „Black Box“-Modell. - Wir wählen eine einzelne Instanz aus dem Testdatensatz aus, für die wir eine Erklärung wünschen.
- Ein
shap.TreeExplainerwird initialisiert. DaRandomForestClassifierein baumbasiertes Modell ist, ist dieser Explainer optimiert und sehr effizient. - Die
explainer.shap_values()-Methode berechnet die SHAP-Werte für unsere ausgewählte Instanz. Diese Werte zeigen, wie stark jedes Merkmal zur Vorhersage für diese spezifische Instanz beiträgt. - Schließlich wird ein
shap.force_plotverwendet, um die Erklärung grafisch darzustellen. Dieses Plot zeigt, wie die einzelnen Merkmale die Vorhersage vom Basiswert (Erwartungswert) zum tatsächlichen Vorhersagewert verschieben.
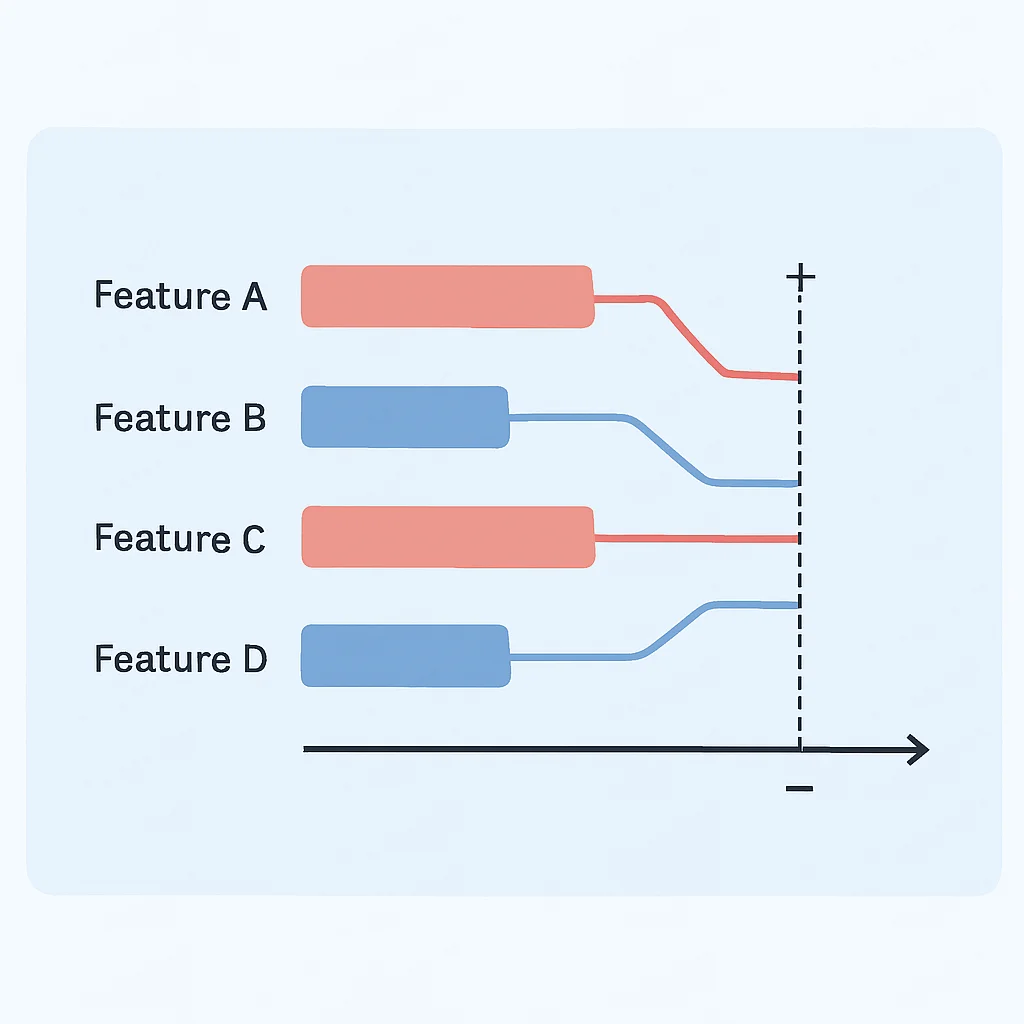
Die Ausgabe des force_plot würde visuell darstellen, welche Merkmale die Vorhersage für die spezifische Iris-Pflanze in Richtung ihrer vorhergesagten Klasse (z.B. „Iris-Virginica“) treiben und welche sie davon abhalten. Rote Werte im Plot erhöhen die Vorhersage, blaue Werte verringern sie.
FAZIT
Fazit und Ausblick auf die Zukunft der XAI
Explainable AI ist im Jahr 2026 keine optionale Ergänzung mehr, sondern ein fundamentaler Pfeiler für die Entwicklung und den Einsatz von KI-Systemen. Sie ermöglicht es Entwicklern, die Komplexität moderner KI-Modelle zu durchdringen, Vertrauen bei Nutzern und Stakeholdern aufzubauen und regulatorische Anforderungen zu erfüllen. Die Fähigkeit, die „Warum“-Frage hinter einer KI-Entscheidung zu beantworten, ist entscheidend für eine verantwortungsvolle und ethische KI-Zukunft.
„Die Zukunft der KI ist erklärbar. Wer heute nicht in XAI investiert, riskiert, morgen den Anschluss an die Innovations- und Vertrauensstandards zu verlieren.“
— Kwonnen, 2026
Zukünftige Trends und Entwicklungen
Die Forschung und Entwicklung im Bereich XAI schreitet rasant voran. Einige der vielversprechendsten Trends für die kommenden Jahre umfassen:
- Multimodale XAI: Erklärungen für KI-Systeme, die Daten aus verschiedenen Modalitäten (z.B. Text, Bild, Audio) verarbeiten, werden immer wichtiger.
- Kausale XAI: Der Übergang von Korrelation zu Kausalität in Erklärungen, um nicht nur zu zeigen, welche Merkmale wichtig sind, sondern auch, wie sie kausal zur Entscheidung beitragen.
- Interaktive und adaptive Erklärungen: Systeme, die Erklärungen an den spezifischen Nutzer und dessen Kontext anpassen und interaktive Exploration ermöglichen.
- XAI für große Sprachmodelle (LLMs): Angesichts der Verbreitung von LLMs ist die Erklärbarkeit ihrer generierten Inhalte und Entscheidungsprozesse ein heißes Forschungsfeld.
KERNPUNKT
XAI wird sich weiterhin zu einem differenzierten und vielschichtigen Feld entwickeln, das sich nicht nur auf die Erklärung von Modellmechanismen konzentriert, sondern auch auf die Bereitstellung nützlicher, kausaler und kontextbezogener Erklärungen für eine breitere Palette von KI-Anwendungen.

Für Entwickler bedeutet dies eine kontinuierliche Weiterbildung und die Bereitschaft, neue Tools und Methoden in ihre Arbeitsabläufe zu integrieren. XAI ist nicht nur ein Werkzeug zur Fehlerbehebung oder Compliance, sondern ein mächtiger Enabler für bessere, fairere und vertrauenswürdigere KI-Systeme. Indem wir die Black Box öffnen, können wir das volle Potenzial der Künstlichen Intelligenz auf verantwortungsvolle Weise ausschöpfen.
FAQ
Häufig gestellte Fragen zu Explainable AI (XAI)
Q. Was ist der Hauptunterschied zwischen lokalen und globalen XAI-Erklärungen?
Lokale Erklärungen konzentrieren sich auf die Begründung einer einzelnen Vorhersage für eine spezifische Eingabe (z.B. warum dieser Kredit abgelehnt wurde). Globale Erklärungen hingegen versuchen, das Gesamtverhalten eines Modells zu erklären, indem sie allgemeine Muster und Feature-Wichtigkeiten über den gesamten Datensatz aufzeigen.
Q. Warum ist XAI im Jahr 2026 besonders relevant?
Die Relevanz von XAI ist im Jahr 2026 aufgrund der zunehmenden Komplexität von KI-Modellen, strengerer gesetzlicher Vorschriften wie dem EU AI Act und dem wachsenden Bedarf an Vertrauen und Rechenschaftspflicht in KI-Systeme stark gestiegen. Unternehmen müssen ihre KI-Entscheidungen nachvollziehbar machen, um Risiken zu minimieren und Akzeptanz zu fördern.
Q. Kann XAI die Genauigkeit eines KI-Modells verbessern?
Direkt verbessert XAI nicht die Genauigkeit eines Modells. Indirekt kann XAI jedoch dazu beitragen, die Modellleistung zu verbessern, indem es Entwicklern hilft, Fehler, Verzerrungen oder unerwünschte Abhängigkeiten in den Daten oder im Modell selbst zu identifizieren. Durch das Verständnis, wie ein Modell Vorhersagen trifft, können gezieltere Optimierungen vorgenommen werden.
Q. Welche XAI-Technik ist die beste?
Es gibt keine „beste“ XAI-Technik; die Wahl hängt stark vom spezifischen Anwendungsfall, dem verwendeten KI-Modell und den Informationsbedürfnissen der Zielgruppe ab. Populäre und vielseitige Methoden sind LIME für lokale Erklärungen und SHAP, das sowohl lokale als auch globale Einblicke bietet und auf einer soliden theoretischen Grundlage basiert.
Q. Welche Rolle spielen XAI-Tools in der Responsible AI?
XAI-Tools sind ein Eckpfeiler von Responsible AI, da sie Transparenz, Fairness und Rechenschaftspflicht ermöglichen. Sie helfen, ethische Bedenken wie Diskriminierung durch algorithmische Verzerrungen zu adressieren, indem sie die zugrunde liegenden Entscheidungsprozesse der KI aufdecken und eine Überprüfung ermöglichen. Dies ist entscheidend für den Aufbau vertrauenswürdiger und gesellschaftlich akzeptierter KI-Systeme.
Danke fürs Lesen!
Wir hoffen, dieser umfassende Leitfaden zu Explainable AI hat Ihnen wertvolle Einblicke und praktische Anleitungen für Ihre KI-Entwicklung im Jahr 2026 gegeben.
Fragen? Schreibt es in die Kommentare!