
ZUSAMMENFASSUNG
[KI & ML] Textanalyse mit vortrainierten NLP-Modellen 2026: Ein praktischer Leitfaden
Erfahre, wie du vortrainierte Natural Language Processing (NLP) Modelle für effektive Textanalyse einsetzt.
Keywords: NLP, Machine Learning, Textanalyse
INHALTSVERZEICHNIS
1. Die wachsende Bedeutung der Textanalyse im Jahr 2026
2. Revolution der Textanalyse: Warum vortrainierte NLP-Modelle?
3. Hugging Face Transformers: Das Ökosystem der Wahl
4. Praktische Anwendungsfälle im Geschäftsalltag 2026
5. Herausforderungen und Lösungsstrategien bei der NLP-Implementierung
6. Schritt-für-Schritt: Ein eigenes Textklassifikationsmodell trainieren
7. Fazit und Ausblick: Die Zukunft der intelligenten Textverarbeitung
1. Die wachsende Bedeutung der Textanalyse im Jahr 2026
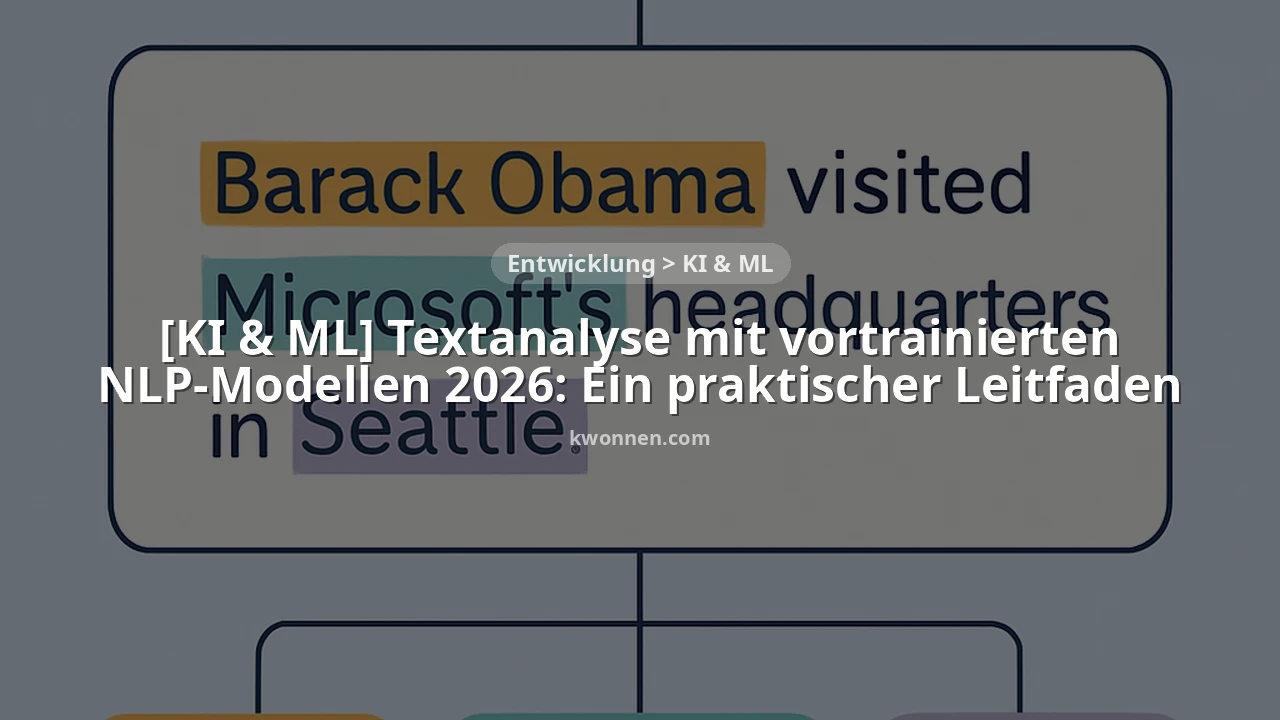
In der heutigen datengesteuerten Welt ist Text die am häufigsten vorkommende Informationsquelle. Ob Kundenrezensionen, soziale Medien, E-Mails, medizinische Berichte oder juristische Dokumente – die Menge an unstrukturierten Textdaten wächst exponentiell. Allein im Jahr 2026 werden Schätzungen zufolge über 80% der Geschäftsdaten in Textform vorliegen, was die manuelle Verarbeitung und Analyse nahezu unmöglich macht.
Hier kommt Natural Language Processing (NLP) ins Spiel. NLP ist ein Teilbereich der Künstlichen Intelligenz, der sich mit der Interaktion zwischen Computern und menschlicher (natürlicher) Sprache befasst. Es ermöglicht Maschinen, Text zu lesen, zu verstehen, zu interpretieren und sogar zu generieren. Traditionell war die Entwicklung effektiver NLP-Systeme eine zeit- und ressourcenintensive Aufgabe, die tiefgreifende Kenntnisse in Linguistik und Machine Learning erforderte.
Doch in den letzten Jahren, insbesondere seit dem Aufkommen von Deep Learning und Transformer-Architekturen, hat sich das Feld dramatisch verändert. Vortrainierte NLP-Modelle haben die Art und Weise revolutioniert, wie Unternehmen und Entwickler Textdaten analysieren. Diese Modelle wurden auf riesigen Textkorpora trainiert, wie beispielsweise dem gesamten Internet, und verfügen über ein tiefes Verständnis für Grammatik, Syntax und Semantik der menschlichen Sprache. Sie können für eine Vielzahl von Aufgaben eingesetzt werden, von der Stimmungsanalyse über die Erkennung benannter Entitäten bis hin zur Textzusammenfassung, und das oft mit beeindruckender Genauigkeit und minimalem Aufwand.
KERNPUNKT
Die manuelle Analyse der exponentiell wachsenden Textdatenmengen ist im Jahr 2026 nicht mehr praktikabel. Vortrainierte NLP-Modelle bieten eine effiziente und hochpräzise Lösung, um diese Daten automatisiert zu verstehen und zu verarbeiten, und sind somit ein unverzichtbares Werkzeug für moderne Unternehmen.
Dieser Leitfaden zielt darauf ab, Entwicklern, Data Scientists und KI-Enthusiasten einen praktischen Überblick über die Anwendung vortrainierter NLP-Modelle zu geben. Wir werden uns auf konkrete Beispiele konzentrieren, die gängigsten Tools und Bibliotheken im Jahr 2026 vorstellen und aufzeigen, wie diese Technologien die KI-Entwicklung beschleunigen und gleichzeitig die Qualität der Ergebnisse verbessern können.

2. Revolution der Textanalyse: Warum vortrainierte NLP-Modelle?
Die Textanalyse hat in den letzten zehn Jahren eine beeindruckende Transformation durchgemacht. Was einst mühsame, regelbasierte Systeme waren, die für jede spezifische Aufgabe manuell angepasst werden mussten, sind heute flexible, lernfähige Modelle, die auf komplexen neuronalen Architekturen basieren.
Die Evolution: Von lexikalisch zu semantisch
Frühe NLP-Methoden, wie die Verwendung von Schlüsselwortlisten, regulären Ausdrücken oder TF-IDF (Term Frequency-Inverse Document Frequency) in Kombination mit traditionellen Machine-Learning-Algorithmen wie Support Vector Machines (SVMs) oder Naive Bayes, konzentrierten sich hauptsächlich auf die lexikalische Ebene der Sprache. Sie konnten zwar Muster in Texten erkennen, hatten aber Schwierigkeiten, den Kontext und die tiefere Bedeutung (Semantik) zu erfassen. Ein Wort wie „Bank“ konnte beispielsweise nicht zwischen einem Finanzinstitut und einem Sitzmöbelstück unterschieden werden, ohne aufwendige manuelle Regelsätze.
Mit dem Aufkommen von Deep Learning, insbesondere seit 2018 mit der Einführung von Transformer-Modellen wie BERT (Bidirectional Encoder Representations from Transformers), hat sich das Blatt gewendet. Diese Modelle sind in der Lage, die komplexen Beziehungen zwischen Wörtern in Sätzen und ganzen Dokumenten zu lernen. Sie berücksichtigen den Kontext bidirektional und können so die Mehrdeutigkeit der Sprache viel besser auflösen.
Die Stärke vortrainierter Modelle: Transfer Learning
Das Hauptkonzept hinter der Effizienz moderner NLP-Modelle ist das Transfer Learning. Anstatt ein Modell von Grund auf neu zu trainieren, was enorme Mengen an Rechenleistung und Daten erfordern würde (oft im Bereich von Terabytes an Text und Wochen von GPU-Zeit), nutzen wir Modelle, die bereits auf riesigen, allgemeinen Textkorpora vortrainiert wurden. Diese Vortrainingsphase befähigt das Modell, ein breites Verständnis für Sprachstrukturen, Faktenwissen und allgemeine Semantik zu entwickeln.
Für spezifische Aufgaben oder Domänen wird das vortrainierte Modell dann mit einem viel kleineren, aufgabenspezifischen Datensatz „feingetunt“ (fine-tuned). Dieser Prozess ist wesentlich schneller und weniger ressourcenintensiv. Beispielsweise kann ein BERT-Modell, das auf Wikipedia und Google Books trainiert wurde, in wenigen Stunden auf einem GPU-Cluster für eine Stimmungsanalyse-Aufgabe auf Kundenrezensionen feingetunt werden, und das mit einer Genauigkeit, die mit traditionellen Methoden kaum zu erreichen wäre.
KERNPUNKT
Vortrainierte NLP-Modelle basieren auf Deep-Learning-Architekturen wie Transformatoren und nutzen Transfer Learning, um ein tiefes Sprachverständnis zu erlangen. Dies ermöglicht eine schnelle und effiziente Anpassung an spezifische Aufgaben mit deutlich geringerem Daten- und Rechenaufwand im Vergleich zu Modellen, die von Grund auf trainiert werden.
Die Vorteile sind klar:
Vorteile
✓ Hohe Genauigkeit: State-of-the-Art-Performance bei den meisten NLP-Aufgaben.
✓ Geringerer Datenbedarf: Benötigen nur kleine, aufgabenspezifische Datensätze für das Fine-Tuning.
✓ Kürzere Entwicklungszeiten: Schnellerer Prototypenbau und Implementierung.
✓ Zugänglichkeit: Viele Modelle sind Open Source und kostenlos verfügbar.
✓ Vielseitigkeit: Anpassbar für eine breite Palette von NLP-Aufgaben.
Nachteile
✗ Ressourcenintensität: Große Modelle erfordern für das Training und die Inferenz oft leistungsstarke Hardware (GPUs).
✗ Komplexität: Die zugrunde liegenden Architekturen sind komplex und erfordern Einarbeitung.
✗ Potenzielle Verzerrungen: Modelle können Verzerrungen aus ihren Trainingsdaten übernehmen.
3. Hugging Face Transformers: Das Ökosystem der Wahl
Im Jahr 2026 ist das Ökosystem von Hugging Face unbestreitbar die zentrale Anlaufstelle für die Arbeit mit vortrainierten NLP-Modellen. Die Firma hat mit ihrer transformers-Bibliothek und dem dazugehörigen Model Hub die Nutzung und Weiterentwicklung von Sprachmodellen demokratisiert.
Die transformers-Bibliothek
Die transformers-Bibliothek bietet eine einheitliche API, um Hunderte von vortrainierten Modellen für Natural Language Understanding (NLU) und Natural Language Generation (NLG) zu nutzen. Sie unterstützt die führenden Deep-Learning-Frameworks PyTorch, TensorFlow und JAX und ermöglicht einen nahtlosen Wechsel zwischen ihnen. Modelle wie BERT, GPT, RoBERTa, XLNet, T5 und viele andere sind hier mit nur wenigen Zeilen Code zugänglich.
Der Hugging Face Model Hub
Der Model Hub ist eine riesige Online-Plattform, auf der Tausende von vortrainierten Modellen von der Community und Forschungseinrichtungen geteilt werden. Nutzer können Modelle hochladen, herunterladen, bewerten und sogar online testen. Dies fördert die Zusammenarbeit und beschleunigt die Forschung und Entwicklung im Bereich NLP immens. Es gibt Modelle für über 100 Sprachen, darunter auch eine Vielzahl von deutschen Modellen, die für spezifische Anwendungsfälle feinabgestimmt sind.
KERNPUNKT
Hugging Face bietet mit der transformers-Bibliothek und dem Model Hub eine standardisierte und zugängliche Plattform für die Nutzung und den Austausch von Tausenden vortrainierter NLP-Modelle. Dies hat die Entwicklung und Implementierung von Sprach-KI im Jahr 2026 maßgeblich vereinfacht und beschleunigt.
Vergleich: Traditionelles ML vs. Vortrainiertes NLP (Stand 2026)
Um die Vorteile noch deutlicher hervorzuheben, betrachten wir einen Vergleich zwischen einem traditionellen Machine-Learning-Ansatz und der Verwendung eines vortrainierten NLP-Modells für eine typische Textklassifikationsaufgabe:
Vergleich: Traditionelles ML vs. Vortrainiertes NLP
Kriterium: Entwicklung von Textklassifikationssystemen
Methode 1 (Traditionelles ML): TF-IDF + Support Vector Machine (SVM)
Methode 2 (Vortrainiertes NLP): BERT / RoBERTa (Fine-Tuning)
Entwicklungszeit:
Methode 1: Tage bis Wochen (Feature Engineering, Modellwahl, Hyperparameter-Optimierung)
Methode 2: Stunden bis wenige Tage (Modellwahl, Fine-Tuning, Hyperparameter-Optimierung)
Datenanforderungen (Trainingsdaten):
Methode 1: Tausende bis Zehntausende gelabelte Beispiele für gute Performance
Methode 2: Hunderte bis wenige Tausend gelabelte Beispiele oft ausreichend
Typische Genauigkeit (F1-Score):
Methode 1: 70-85% (stark abhängig von Daten und Feature Engineering)
Methode 2: 85-95%+ (oft State-of-the-Art, auch mit weniger Daten)
Rechenkosten (Training):
Methode 1: Gering (CPU-basiertes Training oft ausreichend)
Methode 2: Moderat bis hoch (GPU für Fine-Tuning dringend empfohlen)
Wie der Vergleich zeigt, übertreffen vortrainierte Modelle die traditionellen Methoden in den meisten Metriken, insbesondere in Bezug auf die Genauigkeit und den Datenbedarf, was sie zur bevorzugten Wahl für die moderne Textanalyse im Jahr 2026 macht.
CODE-ERKLÄRUNG
Dieses Python-Code-Beispiel zeigt, wie einfach es ist, ein vortrainiertes Modell für die Stimmungsanalyse (Sentiment Analysis) mit der Hugging Face pipeline-Funktion zu nutzen. Es lädt ein Modell, das speziell für die Analyse von Texten in deutscher Sprache trainiert wurde, und wendet es auf zwei Beispieltexte an.
from transformers import pipeline
# Ein vortrainiertes Modell für die Stimmungsanalyse in Deutsch laden
# "oliverguhr/german-sentiment-bert" ist ein populäres Modell für deutsche Texte
sentiment_analyzer = pipeline("sentiment-analysis", model="oliverguhr/german-sentiment-bert")
# Beispieltexte für die Analyse
text_positive = "Ich bin absolut begeistert von diesem Service! Es war eine fantastische Erfahrung."
text_negative = "Die Leistung war enttäuschend und der Support war nicht hilfreich."
text_neutral = "Das Produkt wurde pünktlich geliefert und entsprach der Beschreibung."
# Stimmungsanalyse durchführen
result_positive = sentiment_analyzer(text_positive)
result_negative = sentiment_analyzer(text_negative)
result_neutral = sentiment_analyzer(text_neutral)
# Ergebnisse ausgeben
print(f"Text: \"{text_positive}\"")
print(f"Stimmung: {result_positive[0]['label']} (Score: {result_positive[0]['score']:.4f})\n")
print(f"Text: \"{text_negative}\"")
print(f"Stimmung: {result_negative[0]['label']} (Score: {result_negative[0]['score']:.4f})\n")
print(f"Text: \"{text_neutral}\"")
print(f"Stimmung: {result_neutral[0]['label']} (Score: {result_neutral[0]['score']:.4f})\n")
# Ausgabe könnte sein:
# Text: "Ich bin absolut begeistert von diesem Service! Es war eine fantastische Erfahrung."
# Stimmung: POSITIVE (Score: 0.9989)
#
# Text: "Die Leistung war enttäuschend und der Support war nicht hilfreich."
# Stimmung: NEGATIVE (Score: 0.9986)
#
# Text: "Das Produkt wurde pünktlich geliefert und entsprach der Beschreibung."
# Stimmung: NEUTRAL (Score: 0.9972)
4. Praktische Anwendungsfälle im Geschäftsalltag 2026
Die Vielseitigkeit vortrainierter NLP-Modelle ermöglicht eine breite Palette von Anwendungen in nahezu jeder Branche. Hier sind einige der prominentesten Anwendungsfälle, die im Jahr 2026 von Unternehmen verstärkt genutzt werden:
Kundenfeedback-Analyse und Support-Automatisierung
Unternehmen sammeln riesige Mengen an Kundenfeedback aus Umfragen, sozialen Medien, Produktbewertungen und Support-Tickets. NLP-Modelle können diese Daten automatisch verarbeiten, um Stimmungen zu erkennen (positiv, negativ, neutral), häufige Themen zu identifizieren (z.B. „lange Wartezeiten“, „Produktfehler“) und sogar die Dringlichkeit von Anfragen zu klassifizieren. Ein führendes E-Commerce-Unternehmen konnte beispielsweise im Jahr 2026 durch den Einsatz von NLP die Bearbeitungszeit für Support-Tickets um 30% reduzieren, indem es eingehende Anfragen automatisch priorisierte und an die richtigen Abteilungen weiterleitete.
Anwendungsfall: Kundenfeedback-Analyse
Automatische Erkennung von Stimmung, Themen und Dringlichkeit in Kundenrezensionen und Support-Anfragen zur Verbesserung des Kundenservice und der Produktentwicklung.
Automatisierte Dokumentenverarbeitung in Rechts- und Finanzwesen
In Branchen, die stark von Dokumenten abhängig sind, wie dem Rechts- oder Finanzwesen, können NLP-Modelle enorme Effizienzgewinne erzielen. Sie können Verträge, Finanzberichte oder Compliance-Dokumente analysieren, um spezifische Klauseln, relevante Daten, Parteien oder Risikofaktoren zu extrahieren. Eine große Anwaltskanzlei konnte im letzten Jahr die Zeit für die Due-Diligence-Prüfung bei M&A-Transaktionen um durchschnittlich 40% verkürzen, indem sie NLP für die automatische Erkennung von Schlüsselinformationen in Tausenden von Dokumenten einsetzte.
Anwendungsfall: Dokumentenanalyse
Extraktion von Schlüsselinformationen, Erkennung von Entitäten und Klassifikation von Klauseln in juristischen Verträgen und Finanzberichten.
Medizinische Textanalyse und Forschung
Im Gesundheitswesen können NLP-Modelle klinische Notizen, Patientenakten und medizinische Forschungsartikel analysieren. Sie helfen bei der Extraktion von Diagnosen, Symptomen, Medikamenten, Behandlungen und Patientendemografien. Dies kann die klinische Entscheidungsfindung unterstützen, die Patientenversorgung verbessern und die medizinische Forschung beschleunigen, indem relevante Informationen aus unstrukturierten Texten effizient zugänglich gemacht werden. Eine Studie aus dem Jahr 2026 zeigte, dass NLP die Identifizierung von Patienten für klinische Studien um bis zu 50% effizienter machen kann.
KERNPUNKT
Vortrainierte NLP-Modelle sind im Jahr 2026 zu unverzichtbaren Werkzeugen in vielen Branchen geworden. Sie automatisieren die Analyse großer Textmengen in Bereichen wie Kundenfeedback, Rechtsdokumenten und medizinischer Forschung, was zu erheblichen Effizienzsteigerungen und besseren Entscheidungen führt.
CODE-ERKLÄRUNG
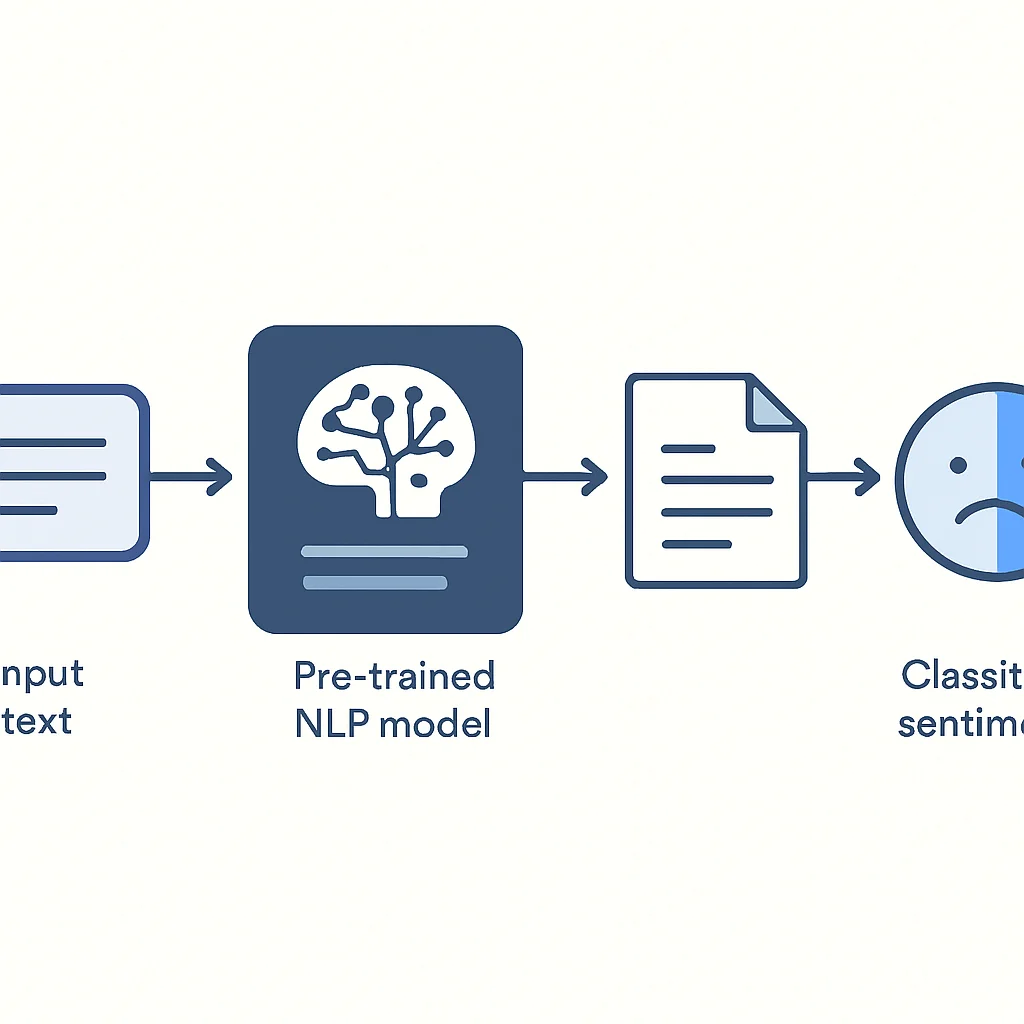
Dieses Beispiel demonstriert die Erkennung benannter Entitäten (Named Entity Recognition, NER) mit einem vortrainierten deutschen Modell. NER ist eine Schlüsselaufgabe im NLP, die dazu dient, wichtige Informationen wie Namen von Personen, Organisationen oder Orten in einem Text zu identifizieren und zu kategorisieren.
from transformers import pipeline
# Ein vortrainiertes Modell für Named Entity Recognition (NER) in Deutsch laden
# "dbmdz/bert-large-cased-finetuned-conll03-german" ist ein Beispiel für ein deutsches NER-Modell
ner_pipeline = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-german", aggregation_strategy="simple")
# Beispieltext für die NER-Analyse
text_ner = "Angela Merkel besuchte Berlin, um sich mit dem Präsidenten der Europäischen Kommission, Ursula von der Leyen, zu treffen. Das Treffen fand im Reichstagsgebäude statt."
# NER durchführen
entities = ner_pipeline(text_ner)
# Ergebnisse ausgeben
print(f"Text für NER: \"{text_ner}\"\n")
print("Gefundene Entitäten:")
for entity in entities:
print(f" Entität: '{entity['word']}', Typ: {entity['entity_group']}, Score: {entity['score']:.4f}")
# Ausgabe könnte sein:
# Text für NER: "Angela Merkel besuchte Berlin, um sich mit dem Präsidenten der Europäischen Kommission, Ursula von der Leyen, zu treffen. Das Treffen fand im Reichstagsgebäude statt."
#
# Gefundene Entitäten:
# Entität: 'Angela Merkel', Typ: PER, Score: 0.9998
# Entität: 'Berlin', Typ: LOC, Score: 0.9997
# Entität: 'Europäischen Kommission', Typ: ORG, Score: 0.9989
# Entität: 'Ursula von der Leyen', Typ: PER, Score: 0.9998
# Entität: 'Reichstagsgebäude', Typ: LOC, Score: 0.9996
5. Herausforderungen und Lösungsstrategien bei der NLP-Implementierung
Obwohl vortrainierte NLP-Modelle die Entwicklung erheblich vereinfachen, gibt es bei ihrer Implementierung und Skalierung immer noch Herausforderungen. Ein fundiertes Verständnis dieser Probleme und der entsprechenden Lösungsstrategien ist entscheidend für den Erfolg von KI-Projekten im Jahr 2026.
Modellgröße und Performance
Moderne Transformer-Modelle sind oft sehr groß, mit Millionen oder sogar Milliarden von Parametern. Dies führt zu hohen Anforderungen an Speicher und Rechenleistung, sowohl während des Trainings (Fine-Tuning) als auch bei der Inferenz (Anwendung des Modells auf neue Daten). Für Echtzeitanwendungen oder den Einsatz auf Edge-Geräten kann dies ein erhebliches Hindernis darstellen.
PROBLEM 01
Hoher Ressourcenbedarf großer NLP-Modelle
Die Größe moderner Transformer-Modelle erschwert den Einsatz in ressourcenbeschränkten Umgebungen oder bei Anforderungen an Echtzeit-Inferenz.
LÖSUNG
Modellkomprimierungstechniken wie Destillation (kleinere Modelle lernen von größeren), Quantisierung (Reduzierung der Präzision von Parametern) und Pruning (Entfernen unwichtiger Parameter) können die Modellgröße und Inferenzzeit erheblich reduzieren, oft mit nur geringem Verlust an Genauigkeit. Tools wie ONNX Runtime oder OpenVINO optimieren die Ausführung zusätzlich.
Domänenspezifische Sprache und Datenmangel
Obwohl vortrainierte Modelle ein allgemeines Sprachverständnis haben, können sie Schwierigkeiten mit hochspezialisierten Domänen haben (z.B. medizinische Fachsprache, juristische Terminologie), für die sie nicht explizit trainiert wurden. Zudem kann es schwierig sein, ausreichend gelabelte Daten für das Fine-Tuning in solchen Nischenbereichen zu beschaffen.
PROBLEM 02
Mangelnde Domänenadaption und begrenzte gelabelte Daten
Allgemeine Modelle performen in spezialisierten Domänen oft schlecht, und das Sammeln gelabelter Daten ist aufwendig.
LÖSUNG
Domänenadaptives Vortraining (z.B. mit Masked Language Modeling auf domänenspezifischen Texten) kann die Modelle auf die neue Terminologie vorbereiten. Für den Datenmangel helfen Weak Supervision (automatische Labelgenerierung), Few-Shot Learning (Anpassung mit sehr wenigen Beispielen) und aktives Lernen (Modell wählt die informativsten ungelabelten Beispiele zur Annotation).
Bias und Fairness
Da NLP-Modelle auf riesigen Textdaten trainiert werden, die oft aus dem Internet stammen, können sie gesellschaftliche Vorurteile und Stereotypen aus diesen Daten lernen und reproduzieren. Dies kann zu diskriminierenden oder unfairen Ergebnissen führen, wenn die Modelle in sensiblen Anwendungen eingesetzt werden (z.B. Personalauswahl, Kreditwürdigkeitsprüfung).
KERNPUNKT
Die Implementierung von NLP-Modellen erfordert im Jahr 2026 die Beachtung von Ressourcenbedarf, Domänenadaption und Bias. Modellkomprimierung, domänenadaptives Vortraining und sorgfältige Bias-Erkennung und -Minderung sind entscheidende Strategien, um diese Herausforderungen erfolgreich zu meistern und faire, effiziente Systeme zu gewährleisten.
PROBLEM 03
Reproduktion von Bias und Stereotypen aus Trainingsdaten
NLP-Modelle können unbewusst gesellschaftliche Vorurteile übernehmen, was zu unfairen oder diskriminierenden Ergebnissen führen kann.
LÖSUNG
Eine sorgfältige Datenbereinigung und das Training auf diversen Datensätzen sind grundlegend. Es gibt auch spezifische Bias-Minderungs-Techniken (z.B. Post-Processing der Embeddings oder der Modellentscheidungen) und Erklärbarkeitstools (XAI), um zu verstehen, warum ein Modell eine bestimmte Entscheidung getroffen hat. Regelmäßige Audits und die Einbeziehung von Ethik-Experten sind ebenfalls unerlässlich.

6. Schritt-für-Schritt: Ein eigenes Textklassifikationsmodell trainieren
Um die praktische Anwendung zu vertiefen, gehen wir die grundlegenden Schritte durch, um ein vortrainiertes NLP-Modell für eine benutzerdefinierte Textklassifikationsaufgabe zu fine-tunen. Wir nutzen hierfür die Hugging Face transformers-Bibliothek, die im Jahr 2026 der De-facto-Standard ist.
Anwendungsbeispiel: Klassifikation von Produktrezensionen
Stellen wir uns vor, wir möchten Produktrezensionen in die Kategorien „positiv“, „negativ“ und „neutral“ klassifizieren. Wir haben einen kleinen Datensatz von 1.000 gelabelten Rezensionen gesammelt.
Schritt 1
Datenvorbereitung: Tokenisierung und Dataset-Erstellung
Zuerst müssen die Texte in eine numerische Form umgewandelt werden, die das Modell verstehen kann. Dies geschieht durch Tokenisierung. Anschließend werden die Daten in ein Format gebracht, das von der Hugging Face Datasets-Bibliothek verarbeitet werden kann.
Schritt 2
Modell laden und für Klassifikation konfigurieren
Wir wählen ein geeignetes vortrainiertes Modell (z.B. bert-base-uncased oder ein deutsches BERT-Modell wie bert-base-german-cased) und laden es. Dann passen wir den letzten Layer des Modells an unsere spezifische Anzahl von Klassen (hier 3: positiv, negativ, neutral) an.
Schritt 3
Training und Evaluierung mit dem Trainer API
Die Trainer-Klasse von Hugging Face vereinfacht den Fine-Tuning-Prozess erheblich. Wir definieren Trainingsargumente (Epochen, Batch-Größe, Lernrate) und übergeben das Modell, den Tokenizer und die Datensätze an den Trainer. Nach dem Training können wir die Leistung des Modells auf einem separaten Validierungsdatensatz bewerten.
KERNPUNKT
Das Fine-Tuning eines vortrainierten NLP-Modells für eine benutzerdefinierte Textklassifikationsaufgabe im Jahr 2026 ist ein standardisierter Prozess: Daten tokenisieren, ein passendes vortrainiertes Modell laden und für die Zielklassen anpassen, und schließlich das Modell mit dem Hugging Face Trainer API effizient trainieren und evaluieren.
CODE-ERKLÄRUNG
Dieses Python-Beispiel skizziert den Fine-Tuning-Prozess für eine Textklassifikationsaufgabe mit einem deutschen BERT-Modell. Es zeigt die Datenvorbereitung mit der Datasets-Bibliothek, das Laden des Modells und Tokenizers sowie die Konfiguration des Trainer-Objekts für das Training. Beachten Sie, dass die eigentlichen Trainingsdaten hier simuliert werden.
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# 1. Beispiel-Daten erstellen (in der Realität aus CSV, JSON etc. laden)
data = {
'text': [
"Dieses Produkt ist fantastisch! Ich liebe es.",
"Ich bin sehr enttäuscht von der Qualität.",
"Es funktioniert, aber es ist nichts Besonderes.",
"Beste Anschaffung des Jahres 2026!",
"Völlig unbrauchbar, pure Zeitverschwendung.",
"Neutraler Kommentar, erfüllt seinen Zweck.",
"Absolut empfehlenswert, top Service!",
"Schlechteste Erfahrung, die ich je hatte.",
"Kann mich nicht beklagen, aber auch nicht loben.",
"Einwandfrei, würde ich wieder kaufen."
],
'label': [0, 1, 2, 0, 1, 2, 0, 1, 2, 0] # 0: Positiv, 1: Negativ, 2: Neutral
}
df = pd.DataFrame(data)
# Mappen der Labels zu Namen für das Modell
id2label = {0: "POSITIVE", 1: "NEGATIVE", 2: "NEUTRAL"}
label2id = {"POSITIVE": 0, "NEGATIVE": 1, "NEUTRAL": 2}
# Dataset-Objekt erstellen
dataset = Dataset.from_pandas(df)
# 2. Tokenizer und Modell laden
# Für deutsche Texte eignet sich "bert-base-german-cased" oder "distilbert-base-german-cased"
model_name = "bert-base-german-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name, num_labels=len(id2label), id2label=id2label, label2id=label2id
)
# Tokenisierungsfunktion
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Daten aufteilen (hier nur ein kleiner Datensatz, in der Realität train/test/val)
# Für dieses Beispiel verwenden wir den gesamten Datensatz als Trainingsdaten
# und simulieren eine kleine Validierung
train_dataset = tokenized_dataset.shuffle(seed=42).select(range(8))
eval_dataset = tokenized_dataset.shuffle(seed=42).select(range(8, 10))
# 3. TrainingArguments und Trainer definieren
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3, # Anzahl der Trainings-Epochen
per_device_train_batch_size=8, # Batch-Größe pro Gerät
per_device_eval_batch_size=8, # Batch-Größe pro Gerät für Evaluierung
warmup_steps=500, # Anzahl der Warmup-Schritte für den Lernraten-Scheduler
weight_decay=0.01, # Stärke der Gewichtsreduktion
logging_dir="./logs", # Verzeichnis für Logs
logging_steps=10,
evaluation_strategy="epoch", # Evaluierung nach jeder Epoche
save_strategy="epoch", # Modell speichern nach jeder Epoche
load_best_model_at_end=True, # Bestes Modell am Ende laden
metric_for_best_model="accuracy",# Metrik zur Bestimmung des besten Modells
)
# Metrik-Funktion definieren
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted', zero_division=0)
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
# Training starten
print("Starte Training...")
trainer.train()
print("Training abgeschlossen.")
# Evaluierung durchführen
print("Starte Evaluierung...")
eval_results = trainer.evaluate()
print(f"Evaluierungsergebnisse: {eval_results}")
# Beispielhafte Vorhersage nach dem Training
# (in der Realität würde man das Modell speichern und später laden)
new_text = "Ich bin mit dem Kauf sehr zufrieden, es übertrifft meine Erwartungen."
inputs = tokenizer(new_text, return_tensors="pt", padding="max_length", truncation=True)
outputs = model(**inputs)
predictions = outputs.logits.argmax(dim=-1).item()
predicted_label = id2label[predictions]
print(f"\nText: '{new_text}' -> Vorhergesagte Stimmung: {predicted_label}")
Häufig gestellte Fragen (FAQ)
Q. Was ist der Hauptvorteil von vortrainierten NLP-Modellen gegenüber traditionellen Methoden?
Der Hauptvorteil liegt im Transfer Learning: Vortrainierte Modelle haben bereits ein tiefes Sprachverständnis erworben und benötigen für spezifische Aufgaben deutlich weniger gelabelte Daten und Rechenzeit beim Fine-Tuning, während sie gleichzeitig eine höhere Genauigkeit erzielen.
Q. Welche Rolle spielt Hugging Face im Ökosystem der NLP-Modelle im Jahr 2026?
Hugging Face ist der De-facto-Standard für NLP. Mit seiner transformers-Bibliothek und dem Model Hub bietet es eine zentrale Plattform, die den Zugang zu Tausenden von vortrainierten Modellen, Tools und Datensätzen für Forschung und Entwicklung demokratisiert.
Q. Sind vortrainierte NLP-Modelle anfällig für Bias?
Ja, da diese Modelle auf riesigen, oft internetbasierten Textkorpora trainiert werden, können sie gesellschaftliche Vorurteile und Stereotypen aus diesen Daten lernen und reproduzieren. Es ist entscheidend, dies durch Datenbereinigung, diverse Trainingsdaten und spezielle Bias-Minderungs-Techniken zu adressieren.
Q. Welche Hardware wird für das Fine-Tuning von NLP-Modellen benötigt?
Für das Fine-Tuning von Transformer-Modellen ist in der Regel eine leistungsstarke GPU (Graphics Processing Unit) dringend empfohlen, da der Prozess rechenintensiv ist. Für die reine Inferenz (Anwendung) können kleinere Modelle oder optimierte Versionen auch auf CPUs oder Edge-Geräten laufen.
7. Fazit und Ausblick: Die Zukunft der intelligenten Textverarbeitung
Die Textanalyse mit vortrainierten NLP-Modellen hat sich im Jahr 2026 als eine der wirkungsvollsten Technologien in der KI-Entwicklung etabliert. Sie ermöglicht es Unternehmen und Entwicklern, aus unstrukturierten Textdaten wertvolle Erkenntnisse zu gewinnen, Prozesse zu automatisieren und innovative Produkte und Dienstleistungen zu schaffen. Die Kombination aus leistungsstarken, vorab trainierten Modellen und benutzerfreundlichen Bibliotheken wie Hugging Face hat die Eintrittsbarriere für die Anwendung von Sprach-KI erheblich gesenkt.
Die Vorteile sind unbestreitbar: signifikante Zeitersparnis, reduzierte Datenanforderungen und eine bemerkenswerte Steigerung der Genauigkeit im Vergleich zu früheren Methoden. Dies hat zu einer Flut von Innovationen in Bereichen wie Kundenmanagement, Dokumentenautomatisierung, medizinischer Diagnostik und vielen anderen geführt.
Zukünftige Entwicklungen
Der Fortschritt im Bereich NLP wird sich voraussichtlich weiter beschleunigen. Wir können im Jahr 2026 und darüber hinaus folgende Trends erwarten:
Zukünftige Trends im NLP
Multimodale Modelle — Integration von Text mit anderen Datenformen wie Bildern, Audio und Video für ein umfassenderes Verständnis.
Effizientere und kleinere Modelle — Weiterentwicklung von Komprimierungstechniken, um große Modelle auch auf Geräten mit begrenzten Ressourcen einsetzen zu können.
Verbesserte Erklärbarkeit und Fairness — Stärkere Fokus auf Transparenz und die Minderung von Bias, um vertrauenswürdige KI-Systeme zu gewährleisten.
Automatisierte Modellentwicklung (AutoNLP) — Tools, die den Prozess der Modellwahl, des Fine-Tunings und der Hyperparameter-Optimierung weiter automatisieren.
Spezialisierte Modelle für Nischenmärkte — Zunehmende Verfügbarkeit von Modellen, die auf sehr spezifische Branchen oder Aufgaben zugeschnitten sind.
Für alle, die in der KI-Entwicklung tätig sind, ist es unerlässlich, mit diesen Entwicklungen Schritt zu halten und die Möglichkeiten, die vortrainierte NLP-Modelle bieten, voll auszuschöpfen. Die Zukunft der Textanalyse ist intelligent, effizient und zugänglicher denn je.
Danke fürs Lesen
Wir hoffen, dieser Leitfaden hat Ihnen wertvolle Einblicke in die Welt der Textanalyse mit vortrainierten NLP-Modellen gegeben und Sie inspiriert, diese leistungsstarken Tools in Ihren eigenen Projekten einzusetzen.
Fragen? Schreibt es in die Kommentare.