

ZUSAMMENFASSUNG
Monitoring & Logging 2026: Prometheus, Grafana und der ELK Stack im Vergleich
Ein umfassender Leitfaden zu den besten Monitoring- und Logging-Lösungen für deine Cloud-Infrastruktur.
Keywords: Prometheus, Grafana, ELK Stack
INHALTSVERZEICHNIS
1. Einleitung: Warum Monitoring & Logging 2026 unverzichtbar sind
2. Prometheus: Metrik-Erfassung und Alarmierung
3. Grafana: Die Visualisierungszentrale
4. Der ELK Stack: Umfassende Log-Analyse
5. Herausforderungen im Monitoring & Logging meistern
6. Praktische Anwendung: Die Wahl der richtigen Tools
7. Häufig gestellte Fragen (FAQ)
8. Fazit und Ausblick
EINLEITUNG
Einleitung: Warum Monitoring & Logging 2026 unverzichtbar sind
In der dynamischen Welt der Cloud-nativen Architekturen und DevOps-Praktiken ist die Fähigkeit, Systeme effektiv zu überwachen und zu protokollieren, nicht länger nur eine Option, sondern eine absolute Notwendigkeit. Im Jahr 2026, in dem Microservices, Container und serverlose Funktionen die Norm sind, kann das Fehlen robuster Monitoring- und Logging-Lösungen schnell zu Betriebsblindheit, längeren Ausfallzeiten und erheblichen Kosten führen. Die Komplexität moderner IT-Infrastrukturen erfordert eine ganzheitliche Sicht, die über das bloße Sammeln von Daten hinausgeht: Es geht um Observability.
Observability, oder Beobachtbarkeit, ist die Fähigkeit, den internen Zustand eines Systems anhand der von ihm ausgegebenen externen Daten (Metriken, Logs und Traces) zu verstehen. Dies ermöglicht es Teams, Probleme proaktiv zu erkennen, deren Ursachen schnell zu isolieren und fundierte Entscheidungen zur Leistungsoptimierung zu treffen. Ohne eine solche Fähigkeit sind Entwicklungs- und Betriebsteams oft im Dunkeln, wenn unerwartete Verhaltensweisen auftreten, was zu Frustration und ineffizienter Fehlerbehebung führt.
KERNPUNKT
Im Jahr 2026 sind robuste Monitoring- und Logging-Lösungen das Rückgrat jeder erfolgreichen Cloud-Strategie, um Observability zu gewährleisten und die Komplexität moderner Infrastrukturen zu beherrschen.
Dieser Leitfaden beleuchtet zwei der populärsten und leistungsfähigsten Ökosysteme für Monitoring und Logging: Prometheus und Grafana für Metrik-basiertes Monitoring sowie den ELK Stack (Elasticsearch, Logstash, Kibana) für umfassende Log-Analyse. Wir werden ihre Architekturen, Stärken und Anwendungsbereiche detailliert untersuchen, um Ihnen zu helfen, die besten Entscheidungen für Ihre spezifischen Anforderungen im Jahr 2026 zu treffen. Von der Echtzeit-Überwachung von Systemressourcen bis zur tiefgehenden Analyse von Anwendungsfehlern – die richtige Kombination dieser Tools kann den Unterschied zwischen reaktiver Problemlösung und proaktiver Systemoptimierung ausmachen.
METRIKEN
Prometheus: Metrik-Erfassung und Alarmierung
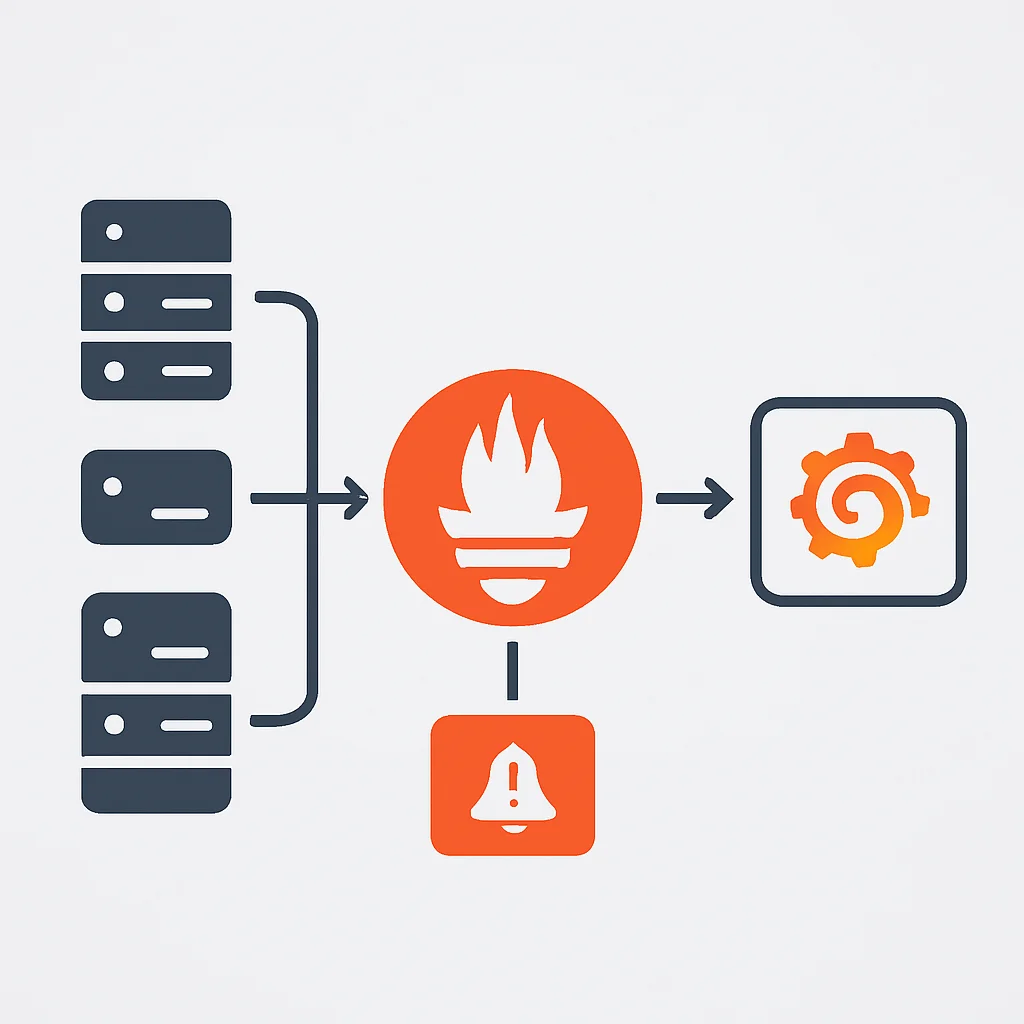
Prometheus hat sich seit seiner Entstehung bei SoundCloud als De-facto-Standard für das Monitoring von Cloud-nativen Umgebungen etabliert, insbesondere in Kombination mit Kubernetes. Es ist ein Open-Source-System zur Überwachung und Alarmierung, das auf einem Pull-Modell basiert. Das bedeutet, dass Prometheus aktiv Endpunkte (sogenannte „Exporters“) abfragt, um Metriken zu sammeln, anstatt darauf zu warten, dass die Anwendungen Metriken pushen.
Architektur und Funktionsweise
Die Kernkomponenten von Prometheus umfassen:
- Prometheus Server: Sammelt Metriken von konfigurierten Zielen in bestimmten Intervallen, speichert die Daten in seiner lokalen Time-Series-Datenbank und führt Regeln aus.
- Client Libraries: Ermöglichen Entwicklern, ihre Anwendungen mit Instrumentierungscode zu versehen, um benutzerdefinierte Metriken zu exponieren.
- Exporters: Kleine Tools, die Metriken von Drittanbieter-Systemen (z.B. Datenbanken, Hardware, HTTP-Server) sammeln und in einem Prometheus-kompatiblen Format bereitstellen. Beispiele sind der Node Exporter für Systemmetriken oder der Blackbox Exporter für Endpunkt-Überwachung.
- Pushgateway: Für kurzlebige Jobs, die nicht lange genug existieren, um von Prometheus gescraped zu werden, können Metriken an das Pushgateway gepusht werden, von wo Prometheus sie dann abruft.
- Alertmanager: Verarbeitet Alarme, die von Prometheus-Servern ausgelöst werden. Er dedupliziert, gruppiert und routet sie an die richtigen Empfänger (E-Mail, PagerDuty, Slack etc.).
- Service Discovery: Prometheus kann sich dynamisch an Veränderungen in Ihrer Infrastruktur anpassen und neue Ziele automatisch erkennen, z.B. über Kubernetes, AWS EC2 oder DNS.
Prometheus speichert alle Metriken als Time-Series-Daten, d.h. als benannte Zeitreihen von Werten. Jede Zeitreihe wird durch ihren Metrik-Namen und eine Reihe von Labels (Schlüssel-Wert-Paaren) eindeutig identifiziert. Diese Labels sind entscheidend für die leistungsstarke Abfragesprache PromQL.
Stärken und Anwendungsfälle
Die Hauptstärken von Prometheus liegen in seiner Effizienz bei der Verarbeitung von Metriken, der Flexibilität durch Exporter und Client Libraries sowie der leistungsstarken Abfragesprache PromQL. PromQL ermöglicht es, komplexe Aggregationen, Filterungen und Berechnungen auf Zeitreihendaten in Echtzeit durchzuführen, was für die Fehlerbehebung und Kapazitätsplanung unerlässlich ist.
Prometheus Vorteile
Cloud-Native optimiert — Ideal für dynamische Umgebungen wie Kubernetes.
Leistungsstarkes PromQL — Flexible Abfragen für detaillierte Metrik-Analysen.
Umfassende Integration — Riesiges Ökosystem an Exportern für diverse Systeme.
Effiziente Alarmierung — Alertmanager zur intelligenten Benachrichtigungsverwaltung.
Typische Anwendungsfälle für Prometheus im Jahr 2026 sind:
- Kubernetes-Cluster-Monitoring: Überwachung von Pods, Nodes, Deployments und Services.
- Anwendungs-Performance-Monitoring (APM): Messung von Latenz, Durchsatz und Fehlerraten von Microservices.
- Infrastruktur-Monitoring: Überwachung von Servern, Datenbanken und Netzwerkgeräten.
- Kapazitätsplanung: Analyse von Ressourcennutzungstrends zur Vorhersage zukünftiger Anforderungen.
CODE-ERKLÄRUNG
Ein einfaches Prometheus-Konfigurationsbeispiel, das zwei Scrape-Jobs definiert: einen für Prometheus selbst und einen für den Node Exporter, der Systemmetriken liefert. Die static_configs definieren die Ziele, die Prometheus abfragen soll.
global:
scrape_interval: 15s # Metriken alle 15 Sekunden abrufen
scrape_configs:
- job_name: 'prometheus'
# Konfiguration für Prometheus selbst
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
# Konfiguration für einen Node Exporter
static_configs:
- targets: ['your_server_ip:9100'] # Ersetzen Sie 'your_server_ip'
relabel_configs:
- source_labels: [__address__]
regex: '([^:]+):.*'
target_label: instance
replacement: '$1'
KERNPUNKT
Prometheus ist die erste Wahl für das Metrik-Monitoring in Cloud-nativen Umgebungen, insbesondere dank seines Pull-Modells, der mächtigen PromQL-Sprache und der engen Integration mit Kubernetes.
VISUALISIERUNG
Grafana: Die Visualisierungszentrale
Während Prometheus hervorragend Metriken sammelt und alarmiert, glänzt Grafana als universelles Open-Source-Tool für die Visualisierung und Analyse dieser Daten. Es ist nicht nur die perfekte Ergänzung zu Prometheus, sondern kann auch eine Vielzahl anderer Datenquellen anzapfen, darunter Elasticsearch, InfluxDB, PostgreSQL, MySQL und Cloud-Dienste wie AWS CloudWatch oder Azure Monitor.
Dashboarding und Datenquellen
Grafana bietet eine intuitive Benutzeroberfläche zur Erstellung interaktiver Dashboards, die Metriken, Logs und Traces in einem einzigen Überblick zusammenfassen können. Die Hauptmerkmale sind:
- Flexible Panels: Eine breite Palette von Visualisierungen, darunter Graphen, Tabellen, Heatmaps, Stat-Panels und mehr, um Daten optimal darzustellen.
- Dynamische Dashboards: Mit Variablen und Templates können Benutzer dynamische Dashboards erstellen, die sich an verschiedene Kontexte anpassen (z.B. verschiedene Server, Anwendungen oder Umgebungen).
- Alerting: Obwohl Prometheus seinen eigenen Alertmanager hat, bietet Grafana auch eine integrierte Alerting-Funktionalität, die auf den Dashboard-Daten basiert und Benachrichtigungen an verschiedene Kanäle senden kann.
- Anmerkungen: Ermöglicht das Hinzufügen von Kontext zu Diagrammen, z.B. um Deployments oder wichtige Ereignisse zu markieren.
- Plugins: Eine umfangreiche Bibliothek von Plugins erweitert die Funktionalität von Grafana um neue Datenquellen, Panels oder Authentifizierungsmethoden.
Die Integration von Grafana mit Prometheus ist nahtlos. Nachdem Prometheus als Datenquelle in Grafana konfiguriert wurde, können PromQL-Abfragen direkt in den Panels verwendet werden, um die gesammelten Metriken zu visualisieren.

Synergien und Best Practices
Die Kombination von Prometheus und Grafana ist ein mächtiges Duo für das Monitoring. Prometheus sammelt die Rohdaten und löst Alarme aus, während Grafana diese Daten in aussagekräftige Visualisierungen umwandelt, die von Entwicklern, Operations-Teams und sogar Management verstanden werden können. Diese Trennung der Aufgaben führt zu einer robusten und skalierbaren Monitoring-Lösung.
Grafana Vorteile
Universelle Datenquelle — Verbindet sich mit einer Vielzahl von Datenbanken und Diensten.
Intuitive Dashboards — Einfache Erstellung und Anpassung von Visualisierungen.
Starke Community — Tausende von vorgefertigten Dashboards und Plugins verfügbar.
Kollaboration — Ermöglicht das Teilen und Verwalten von Dashboards im Team.
Best Practices für Grafana im Jahr 2026 umfassen:
- Dashboard-as-Code: Speichern Sie Ihre Grafana-Dashboards als JSON-Dateien in einem Versionskontrollsystem, um Änderungen zu verfolgen und die Bereitstellung zu automatisieren.
- Templating nutzen: Erstellen Sie flexible Dashboards mit Variablen, um die Wiederverwendbarkeit zu maximieren und die Anzahl der Dashboards zu reduzieren.
- Alerting-Strategie: Kombinieren Sie Prometheus Alertmanager für kritische Service-Level-Alerts und Grafana-Alerts für Dashboard-spezifische Schwellenwerte, um eine umfassende Alarmierungsstrategie zu gewährleisten.
- Performance-Optimierung: Achten Sie auf die Komplexität Ihrer PromQL-Abfragen in Grafana, um die Ladezeiten der Dashboards zu minimieren.
CODE-ERKLÄRUNG
Ein stark vereinfachter JSON-Ausschnitt eines Grafana-Dashboard-Panels. Er zeigt, wie eine PromQL-Abfrage (up{job="prometheus"}) verwendet wird, um den Status des Prometheus-Servers anzuzeigen.
{
"panels": [
{
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {
"custom": {},
"max": 1,
"min": 0,
"thresholds": {
"mode": "absolute",
"steps": [
{ "color": "#e03131", "value": null },
{ "color": "#2b8a3e", "value": 1 }
]
},
"unit": "short"
},
"overrides": []
},
"gridPos": { "h": 8, "w": 12, "x": 0, "y": 0 },
"id": 2,
"options": {
"orientation": "auto",
"reduceOptions": { "calcs": [ "lastNotNull" ] }
},
"pluginViz": "stat",
"targets": [
{
"expr": "up{job=\"prometheus\"}",
"refId": "A"
}
],
"title": "Prometheus Server Status",
"type": "stat"
}
],
"title": "Basic Prometheus Overview"
}
KERNPUNKT
Grafana ist die vielseitige Visualisierungsplattform, die Metriken aus Prometheus und Logs aus dem ELK Stack in ansprechenden, interaktiven Dashboards zusammenführt und so eine zentrale Beobachtungszentrale schafft.
LOGS
Der ELK Stack: Umfassende Log-Analyse
Der ELK Stack, bestehend aus Elasticsearch, Logstash und Kibana, ist eine leistungsstarke Sammlung von Open-Source-Tools, die speziell für das Sammeln, Verarbeiten, Speichern und Visualisieren von Log-Daten entwickelt wurden. Während Metriken einen schnellen Überblick über den Systemzustand geben, bieten Logs die detaillierte „Kriminalgeschichte“, die für die Ursachenanalyse (Root Cause Analysis) von Fehlern unerlässlich ist.
Elasticsearch: Die Suchmaschine für Logs
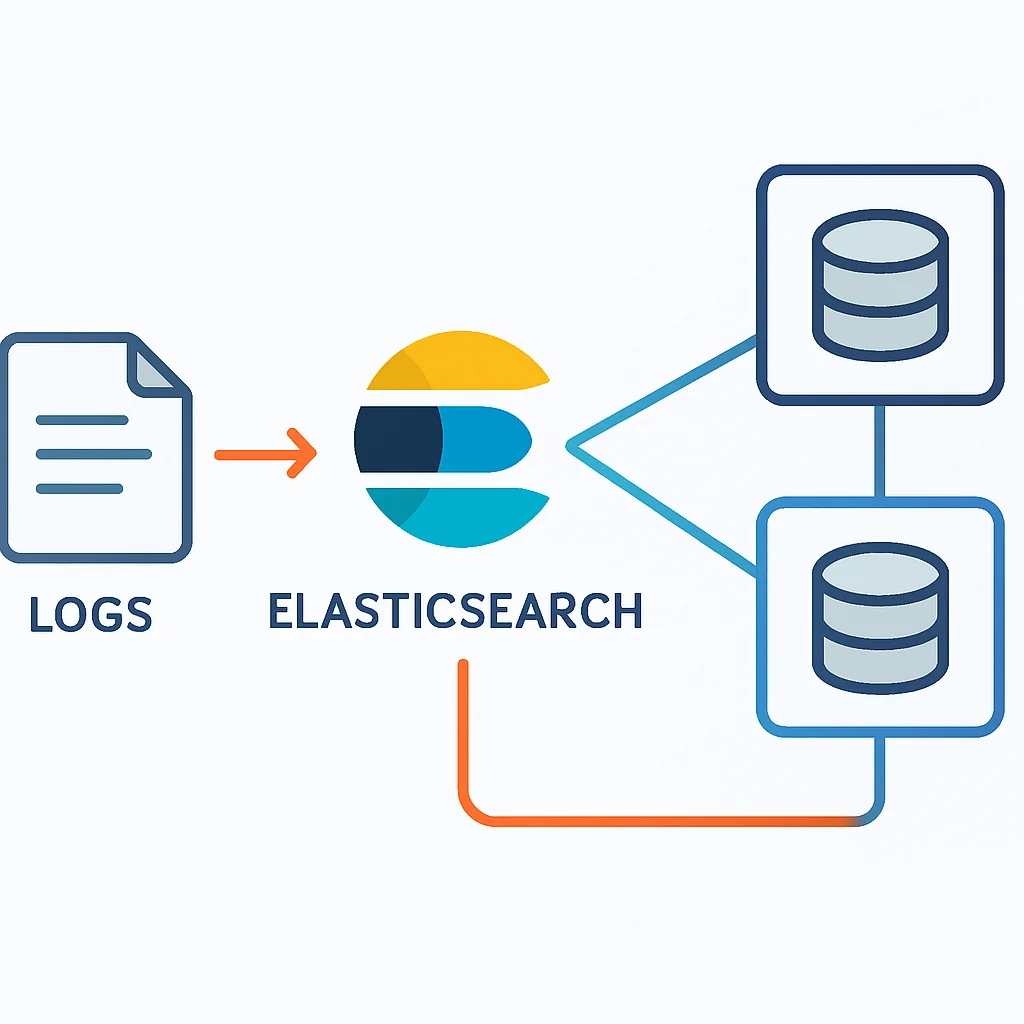
Elasticsearch ist das Herzstück des ELK Stacks. Es ist eine hochskalierbare, verteilte Full-Text-Suchmaschine, die auf Apache Lucene basiert. Es speichert Daten in einem dokumentenorientierten Format (JSON) und ermöglicht schnelle Suchanfragen, Aggregationen und Analysen großer Mengen von strukturierten und unstrukturierten Daten. Für Logs bedeutet dies, dass Sie in Millisekunden Milliarden von Logzeilen durchsuchen können, um spezifische Fehlermeldungen, Benutzeraktivitäten oder Performance-Engpässe zu finden.
- Indizes: Logs werden in Indizes organisiert, die wie Tabellen in einer relationalen Datenbank funktionieren.
- Dokumente: Jede Logzeile oder jedes Ereignis wird als JSON-Dokument gespeichert.
- Sharding & Replikation: Elasticsearch verteilt Daten über mehrere Knoten (Shards) und erstellt Kopien (Replicas) für hohe Verfügbarkeit und Skalierbarkeit.
CODE-ERKLÄRUNG
Ein Beispiel für eine einfache Elasticsearch-Abfrage, die nach Log-Einträgen mit dem Feld level gleich ERROR im Index my-application-logs-2026.04.07 sucht.
GET /my-application-logs-2026.04.07/_search
{
"query": {
"match": {
"level": "ERROR"
}
},
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
],
"size": 10
}
Logstash: Die Datenpipeline
Logstash ist ein serverseitiges Datenverarbeitungstool, das Daten aus verschiedenen Quellen gleichzeitig aufnimmt, transformiert und an verschiedene Ziele sendet. Es fungiert als ETL-Tool (Extract, Transform, Load) für Logs und andere Ereignisdaten.
- Input Plugins: Sammeln Daten aus Quellen wie Dateien, Syslog, Kafka, RabbitMQ oder Beats.
- Filter Plugins: Verarbeiten und transformieren die Daten. Dies beinhaltet das Parsen unstrukturierter Logs (z.B. mit Grok), das Hinzufügen von Geo-Informationen, das Filtern sensibler Daten und das Normalisieren von Feldern.
- Output Plugins: Senden die verarbeiteten Daten an Ziele wie Elasticsearch, S3, oder andere Datenbanken.
CODE-ERKLÄRUNG
Ein einfaches Logstash-Konfigurationsbeispiel. Es liest Daten von einem TCP-Port, parst sie mit einem Grok-Filter und sendet sie dann an einen Elasticsearch-Host. Grok ist ein leistungsstarkes Tool zum Parsen unstrukturierter Log-Daten in strukturierte Felder.
input {
tcp {
port => 5000
codec => json_lines
}
}
filter {
# Beispiel für Grok-Filter, um eine Logzeile zu parsen
# Angenommen, Ihre Logs sehen so aus: "2026-04-07 10:00:00 [INFO] User X logged in."
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{LOGLEVEL:level}\] %{GREEDYDATA:log_message}" }
}
date {
match => [ "timestamp", "YYYY-MM-dd HH:mm:ss" ]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "my-app-logs-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
Kibana: Die Visualisierungs- und Management-Oberfläche
Kibana ist die Web-Benutzeroberfläche des ELK Stacks. Es ermöglicht Benutzern, Logs und Ereignisdaten in Elasticsearch zu durchsuchen, zu analysieren und zu visualisieren. Mit Kibana können Sie:
- Discover: Rohe Log-Daten durchsuchen, filtern und untersuchen.
- Visualize: Interaktive Diagramme, Karten und andere Visualisierungen erstellen.
- Dashboards: Mehrere Visualisierungen zu einem einzigen Dashboard kombinieren, um einen umfassenden Überblick zu erhalten.
- Dev Tools: Direkte Interaktion mit Elasticsearch über eine Konsolen-Schnittstelle.
- Stack Management: Indizes, Benutzer und Rollen verwalten.
Beats: Leichte Datenversender
Neben Logstash bietet das Elastic-Ökosystem auch eine Familie von „Beats“ – leichten, spezialisierten Datenversendern. Die bekanntesten sind:
- Filebeat: Sammelt Log-Dateien von Servern und sendet sie an Logstash oder Elasticsearch.
- Metricbeat: Sammelt System- und Service-Metriken (CPU, Speicher, Festplatte, Docker, Kubernetes etc.) und sendet sie an Logstash oder Elasticsearch.
Beats sind ressourcenschonender als Logstash und werden oft direkt auf den zu überwachenden Systemen installiert, um Daten effizient an eine zentrale Logstash-Instanz zur weiteren Verarbeitung oder direkt an Elasticsearch zu senden.
KERNPUNKT
Der ELK Stack ist unübertroffen für die zentrale Erfassung, Verarbeitung, Speicherung und Analyse großer Mengen von Log-Daten, und bietet tiefe Einblicke in Systemfehler, Sicherheitsereignisse und Anwendungsperformance.
HERAUSFORDERUNGEN
Herausforderungen im Monitoring & Logging meistern
Obwohl Prometheus/Grafana und der ELK Stack leistungsstarke Werkzeuge sind, bringen sie, insbesondere in großen Cloud-Umgebungen, auch eigene Herausforderungen mit sich. Eine effektive Observability-Strategie muss diese Hürden proaktiv angehen.
PROBLEM 01
Exponentielles Datenvolumen und Kosten
Mit der Zunahme von Microservices und Container-Instanzen explodiert das Volumen der Metrik- und Log-Daten. Dies führt zu erheblichen Speicher- und Verarbeitungskosten, insbesondere bei Cloud-basierten Diensten.
LÖSUNG — Intelligente Datenverwaltung
Implementieren Sie eine mehrstufige Speicherstrategie. Für Prometheus bedeutet dies, alte Daten zu downsamplen oder an Langzeitspeicherlösungen wie Thanos oder Mimir auszulagern. Für den ELK Stack nutzen Sie Index Lifecycle Management (ILM), um Indizes automatisch nach einer bestimmten Zeitspanne in kostengünstigere Speicher-Tiers zu verschieben oder zu löschen. Auch das Filtern unnötiger Logs und Metriken an der Quelle reduziert das Volumen erheblich.
PROBLEM 02
Alert Fatigue (Alarmmüdigkeit)
Eine Flut von Alarmen, die nicht kritisch sind oder nicht handlungsrelevant, führt dazu, dass Teams echte Probleme übersehen oder ignorieren. Dies untergräbt das Vertrauen in das Monitoring-System.
LÖSUNG — Intelligente Alarmierungsstrategien
Konzentrieren Sie sich auf serviceorientierte Alarme (SLOs/SLIs) statt auf reine Ressourcenalarme. Nutzen Sie den Prometheus Alertmanager zur Gruppierung, Deduplizierung und Stummschaltung von Alarmen. Implementieren Sie Schwellenwerte mit „for“-Klauseln, um zu verhindern, dass temporäre Spitzen Alarme auslösen. Ergänzen Sie dies mit Anomaly Detection (z.B. über Machine Learning-Funktionen in Elastic Stack), um subtile Änderungen zu erkennen, die normale Schwellenwerte übersehen würden. Jede Alarmierung sollte eine klare Handlungsempfehlung oder einen Link zu einem Runbook enthalten.
PROBLEM 03
Komplexe Integration und Wartung
Die Einrichtung und Pflege einer Observability-Pipeline, die Metriken, Logs und Traces aus heterogenen Systemen sammelt, kann komplex und zeitaufwändig sein, insbesondere in schnelllebigen DevOps-Umgebungen.
LÖSUNG — Automatisierung und Standardisierung
Nutzen Sie Infrastructure as Code (IaC) Tools wie Terraform oder Ansible, um die Bereitstellung und Konfiguration von Prometheus, Grafana und dem ELK Stack zu automatisieren. Standardisieren Sie Log-Formate (z.B. JSON) und Metrik-Benennungskonventionen, um die Verarbeitungs- und Abfrageeffizienz zu verbessern. Setzen Sie auf OpenTelemetry als Standard für die Instrumentierung von Anwendungen, um die Sammlung von Metriken, Logs und Traces zu vereinheitlichen und die Vendor-Lock-in zu reduzieren. Dies vereinfacht die Integration und reduziert den Wartungsaufwand erheblich.
KERNPUNKT
Die Bewältigung von Datenvolumen, Alert Fatigue und Integrationskomplexität erfordert im Jahr 2026 eine Kombination aus intelligenten Datenmanagement-Strategien, serviceorientierter Alarmierung und umfassender Automatisierung mit Tools wie OpenTelemetry und IaC.
ANWENDUNG
Praktische Anwendung: Die Wahl der richtigen Tools
Die Entscheidung, ob Prometheus/Grafana, der ELK Stack oder eine Kombination aus beiden die beste Lösung ist, hängt stark von den spezifischen Anforderungen und der Art der zu überwachenden Systeme ab. Im Jahr 2026 ist die Tendenz, eine hybride Strategie zu verfolgen, weit verbreitet, da Metriken und Logs komplementäre Einblicke liefern.
Wann Prometheus & Grafana?
Prometheus und Grafana sind die ideale Wahl, wenn Ihr Fokus auf den folgenden Bereichen liegt:
- Echtzeit-Metrik-Monitoring: Sie benötigen präzise, numerische Daten über die Leistung und den Zustand Ihrer Systeme in nahezu Echtzeit (z.B. CPU-Auslastung, Speichernutzung, Request-Latenz).
- Cloud-Native-Umgebungen: Sie betreiben Kubernetes oder andere Container-Orchestrierungsplattformen, für die Prometheus eine native Unterstützung und eine Fülle von Exportern bietet.
- Proaktive Alarmierung: Sie möchten schnell benachrichtigt werden, wenn bestimmte Schwellenwerte überschritten werden oder Anomalien in Metrik-Trends auftreten.
- Kapazitätsplanung: Sie analysieren langfristige Metrik-Trends, um Ressourcenbedarf und Skalierungsanforderungen zu prognostizieren.
Anwendungsfall: Microservice-Performance
Überwachung der Request-Rate, Fehlerrate und Latenz von REST-APIs in einem Kubernetes-Cluster. Prometheus sammelt die Metriken, Grafana visualisiert sie in einem Dashboard und der Alertmanager benachrichtigt bei Überschreitung von Schwellenwerten.
Wann der ELK Stack?
Der ELK Stack ist die bessere Wahl, wenn Ihre Anforderungen sich auf die Analyse von Log-Daten konzentrieren:
- Detaillierte Fehleranalyse: Sie müssen die genaue Abfolge von Ereignissen verstehen, die zu einem Fehler geführt haben, und Stack Traces oder detaillierte Fehlermeldungen analysieren.
- Sicherheits- und Audit-Logging: Sie müssen alle Benutzeraktivitäten, Zugriffsversuche und Systemänderungen protokollieren und durchsuchen, um Compliance-Anforderungen zu erfüllen oder Sicherheitsvorfälle zu untersuchen.
- Full-Text-Search auf Logs: Sie müssen komplexe Suchanfragen auf unstrukturierten oder semi-strukturierten Log-Daten durchführen können, um Muster zu erkennen oder spezifische Ereignisse zu finden.
- Business Intelligence aus Logs: Sie extrahieren Informationen aus Logs, um Geschäftsprozesse zu analysieren (z.B. Klickpfade auf einer Website, Konversionsraten aus Anwendungs-Logs).
Anwendungsfall: Fehlerbehebung und Compliance
Zentrale Erfassung aller Anwendungs- und System-Logs. Ein Entwickler kann nach einer bestimmten Transaktions-ID suchen, um alle zugehörigen Log-Einträge über verschiedene Microservices hinweg zu finden und so schnell die Ursache eines Kundenproblems zu identifizieren. Auditoren können Zugriffslogs durchsuchen, um Compliance-Nachweise zu erbringen.
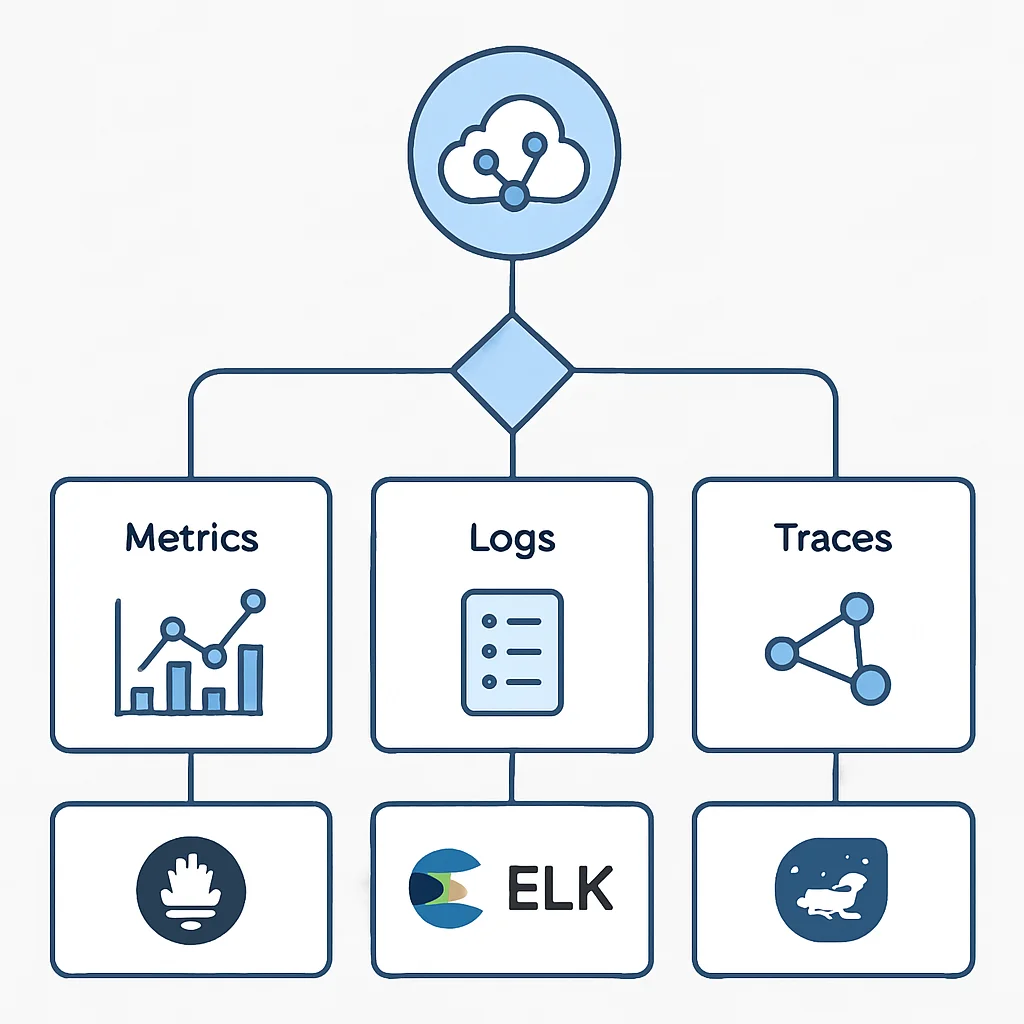
Die Kombination: Metriken und Logs für umfassende Observability
Für die meisten modernen Cloud-Umgebungen im Jahr 2026 ist die effektivste Strategie, sowohl Prometheus/Grafana als auch den ELK Stack zu nutzen. Sie ergänzen sich perfekt:
- Metriken geben Ihnen einen schnellen Überblick über den Zustand des Systems und alarmieren bei Problemen.
- Logs liefern die detaillierten Informationen, um die Ursache dieser Probleme zu finden.
Ein typischer Workflow wäre: Ein Prometheus-Alarm wird ausgelöst, der auf ein erhöhtes Fehleraufkommen in einem Service hinweist. Das Team wechselt dann zu einem Grafana-Dashboard, das sowohl Metriken als auch aggregierte Log-Informationen des betroffenen Services anzeigt. Von dort aus kann direkt in Kibana gesprungen werden, um die spezifischen Log-Einträge zu durchsuchen und die genaue Fehlermeldung oder den Kontext des Problems zu identifizieren.
KERNPUNKT
Die optimale Observability-Strategie im Jahr 2026 integriert Prometheus/Grafana für leistungsstarkes Metrik-Monitoring und den ELK Stack für tiefgehende Log-Analyse, um sowohl den Überblick als auch die Detailtiefe für die Fehlerbehebung und Performance-Optimierung zu gewährleisten.
Häufig gestellte Fragen (FAQ)
Q. Was ist der Hauptunterschied zwischen Metriken und Logs?
A. Metriken sind aggregierte, numerische Messwerte, die den Zustand eines Systems zu einem bestimmten Zeitpunkt beschreiben (z.B. CPU-Auslastung). Logs sind diskrete, zeitgestempelte Ereignisse, die detaillierte Informationen über das Geschehen in einem System liefern (z.B. Fehlermeldungen, Benutzeraktionen).
Q. Kann ich Prometheus und den ELK Stack zusammen verwenden?
A. Ja, absolut. Tatsächlich ist dies die empfohlene Vorgehensweise für umfassende Observability. Prometheus und Grafana werden für Metriken und Echtzeit-Alarmierung eingesetzt, während der ELK Stack für die tiefgehende Log-Analyse und Fehlersuche verwendet wird. Grafana kann sogar Dashboards erstellen, die Daten aus beiden Quellen anzeigen.
Q. Was ist Observability und wie unterscheidet es sich von Monitoring?
A. Monitoring konzentriert sich darauf, bekannte Probleme zu erkennen und Schwellenwerte zu überwachen. Observability hingegen ist die Fähigkeit, den internen Zustand eines Systems anhand seiner externen Ausgaben (Metriken, Logs, Traces) zu verstehen, auch für unbekannte Probleme. Es ermöglicht, Fragen zu stellen, die man vorher nicht kannte.
Q. Welche Rolle spielen „Beats“ im ELK Stack?
A. Beats sind leichte Datenversender, die auf den zu überwachenden Systemen installiert werden, um spezifische Daten (z.B. Logs mit Filebeat, Metriken mit Metricbeat) effizient zu sammeln und an Logstash oder direkt an Elasticsearch zu senden. Sie sind eine ressourcenschonende Alternative zu Logstash für die Datenerfassung am Rande des Netzwerks.
Q. Ist OpenTelemetry relevant für Prometheus oder den ELK Stack?
A. Ja, OpenTelemetry ist hochrelevant. Es ist ein Vendor-neutraler Standard für die Instrumentierung von Anwendungen, um Metriken, Logs und Traces zu generieren und zu exportieren. Es kann als einheitliche Sammelstelle dienen, um Daten an Prometheus (für Metriken) und den ELK Stack (für Logs und Traces) zu senden, was die Integration und Wartung erheblich vereinfacht.
FAZIT
Fazit und Ausblick
Monitoring und Logging sind die Eckpfeiler einer stabilen und performanten Cloud-Infrastruktur im Jahr 2026. Prometheus und Grafana bieten eine unschlagbare Kombination für das Metrik-basierte Monitoring und die Visualisierung, ideal für Cloud-native Umgebungen und proaktive Alarmierung. Der ELK Stack hingegen ist der Goldstandard für die zentrale Erfassung, Verarbeitung und tiefe Analyse von Log-Daten, unverzichtbar für die Ursachenanalyse, Sicherheit und Compliance.
Die Zukunft der Observability wird weiterhin von der Konvergenz dieser Datenarten geprägt sein. Standards wie OpenTelemetry werden eine immer wichtigere Rolle spielen, um die Instrumentierung zu vereinheitlichen und die Übertragbarkeit von Daten zwischen verschiedenen Systemen zu gewährleisten. Auch der Einsatz von Künstlicher Intelligenz (KI) und Machine Learning (ML) zur automatischen Erkennung von Anomalien und zur Reduzierung von Alert Fatigue wird weiter zunehmen. Der Schlüssel zum Erfolg liegt darin, die richtigen Tools für die richtigen Aufgaben zu wählen und sie intelligent zu integrieren, um eine umfassende und verwertbare Sicht auf Ihre Systeme zu erhalten.
KERNPUNKT
Eine zukunftssichere Observability-Strategie im Jahr 2026 kombiniert die Stärken von Prometheus/Grafana und dem ELK Stack, nutzt OpenTelemetry für Standardisierung und integriert KI/ML für intelligentere Analysen und Alarmierungen.
Danke fürs Lesen!
Wir hoffen, dieser Leitfaden hat Ihnen geholfen, die Welt des Monitorings und Loggings im Jahr 2026 besser zu verstehen.
Fragen? Schreibt es in die Kommentare!